sentinel
sentinel
Smith微服务保护
1.初识Sentinel
1.1.雪崩问题及解决方案
1.1.1.雪崩问题
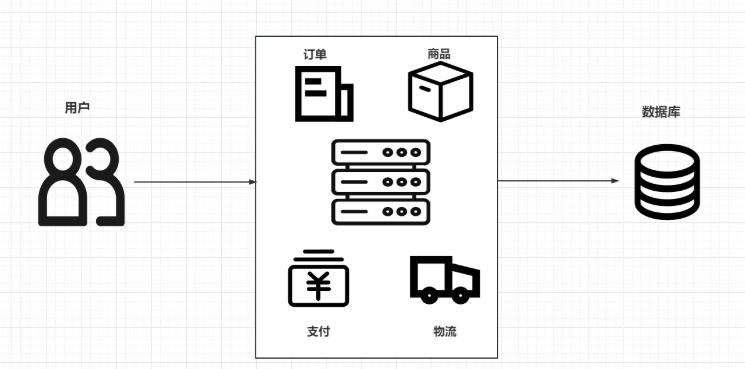
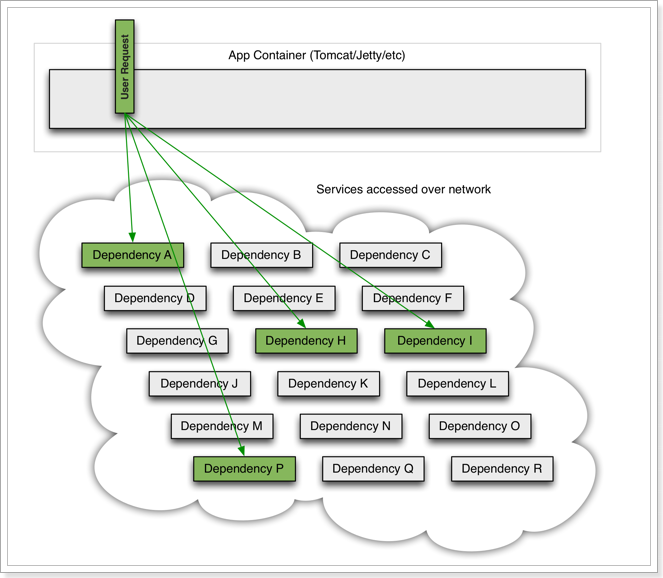
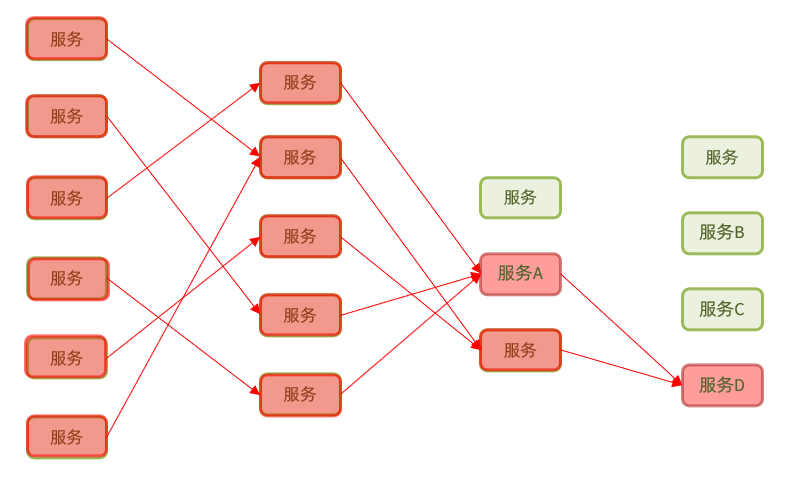
微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。
如图,如果服务提供者I发生了故障,当前的应用的部分业务因为依赖于服务I,因此也会被阻塞。此时,其它不依赖于服务I的业务似乎不受影响。
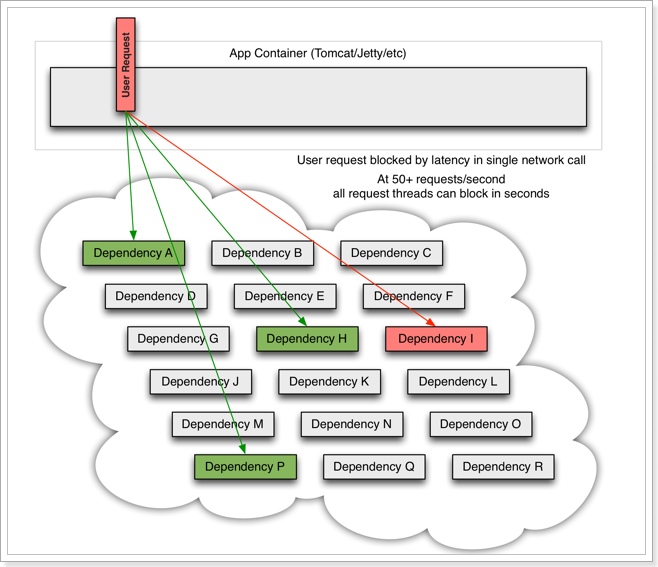
但是,依赖服务I的业务请求被阻塞,用户不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:
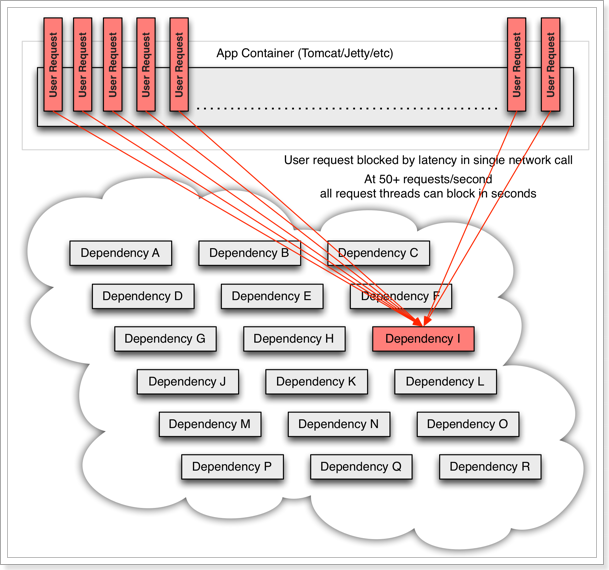
服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,那么当前服务也就不可用了。
那么,依赖于当前服务的其它服务随着时间的推移,最终也都会变的不可用**,形成级联失败,雪崩就发生了**:
1.1.2.超时处理
解决雪崩问题的常见方式有四种:
•超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
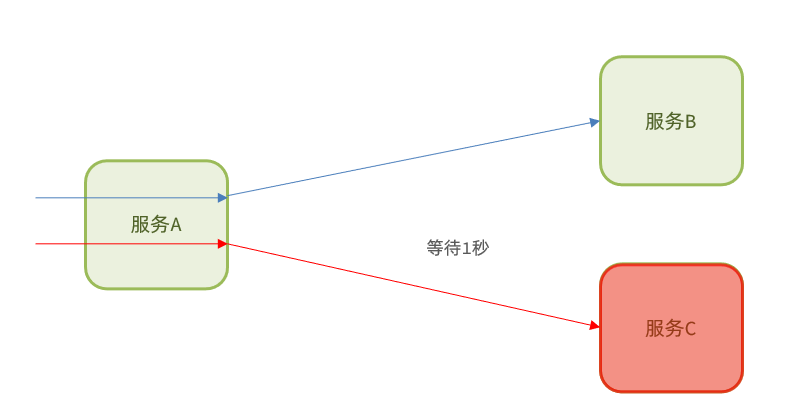
1.1.3.仓壁模式
方案2:仓壁模式
仓壁模式来源于船舱的设计:
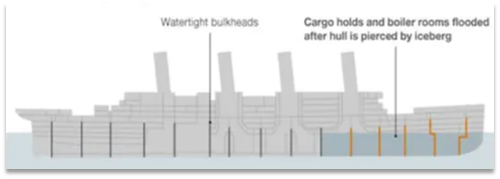
船舱都会被隔板分离为多个独立空间,当船体破损时,只会导致部分空间进入,将故障控制在一定范围内,避免整个船体都被淹没。
于此类似,我们可以限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。
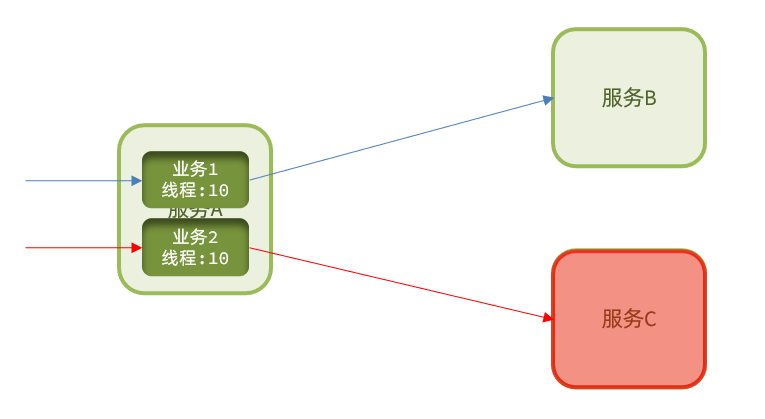
1.1.4.断路器
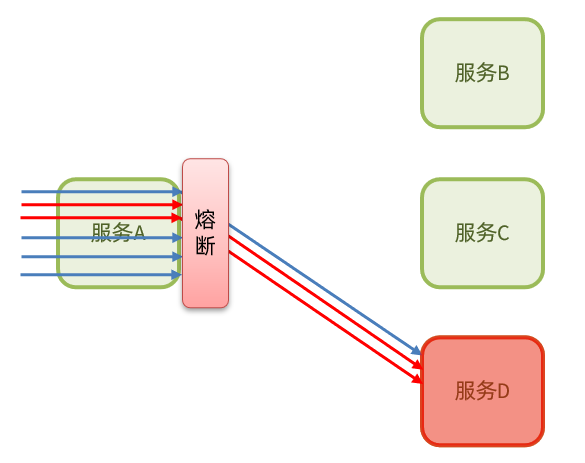
断路器模式:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
断路器会统计访问某个服务的请求数量,异常比例:
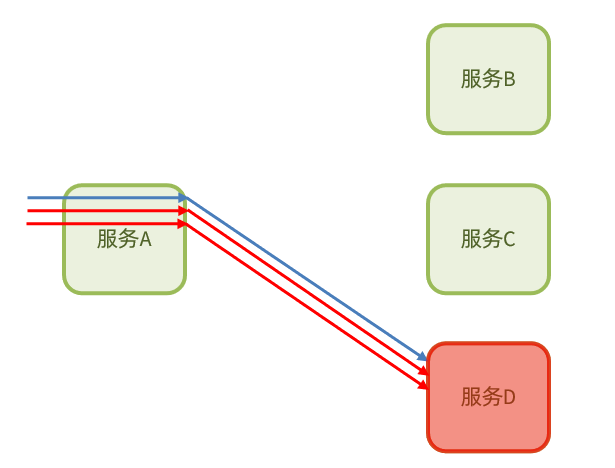
当发现访问服务D的请求异常比例过高时,认为服务D有导致雪崩的风险,会拦截访问服务D的一切请求,形成熔断:
1.1.5.限流
流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。 削峰填谷

1.1.6.总结
什么是雪崩问题?
- 微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
可以认为:
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
1.2.常用的服务保护技术
在SpringCloud当中支持多种服务保护技术:
早期比较流行的是Hystrix框架,但目前国内实用最广泛的还是阿里巴巴的Sentinel框架
1.3.Sentinel介绍和安装
1.3.1.初识Sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:https://sentinelguard.io/zh-cn/index.html
Sentinel 具有以下特征:
•丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
•完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
•广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
1.3.2.安装Sentinel
1)下载
sentinel官方提供了UI控制台,方便我们对系统做限流设置。大家可以在GitHub下载。
课前资料也提供了下载好的jar包:
2)运行
将jar包放到任意非中文目录,执行命令:
1 | java -jar sentinel-dashboard-1.8.8.jar |
如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| server.port | 8080 | 服务端口 |
| sentinel.dashboard.auth.username | sentinel | 默认用户名 |
| sentinel.dashboard.auth.password | sentinel | 默认密码 |
例如,修改端口:
1 | java -Dserver.port=8888 -jar sentinel-dashboard-1.8.8.jar |
3)访问
访问http://localhost:8080页面,就可以看到sentinel的控制台了:

需要输入账号和密码,默认都是:sentinel
1.4.微服务整合Sentinel
我们在cjc-seckill-service中整合sentinel,并连接sentinel的控制台,步骤如下:
1)引入sentinel依赖
1 | <!--sentinel--> |
2)配置控制台
修改application.yaml文件,添加下面内容:
1 | server: |
3)访问cjc-service的任意端点
打开浏览器,访问,这样才能触发sentinel的监控。
然后再访问sentinel的控制台,查看效果:
2.流量控制
雪崩问题虽然有四种方案,但是限流是避免服务因突发的流量而发生故障,是对微服务雪崩问题的预防。我们先学习这种模式。
2.1.簇点链路
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint,也就是controller中的方法),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
例如,我们刚才访问的dd-seckill-service中的SeckillController中的端点:/seckill/getRedis

流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则:
- 流控:流量控制
- 降级:降级熔断
- 热点:热点参数限流,是限流的一种
- 授权:请求的权限控制
2.1.快速入门
2.1.1.示例
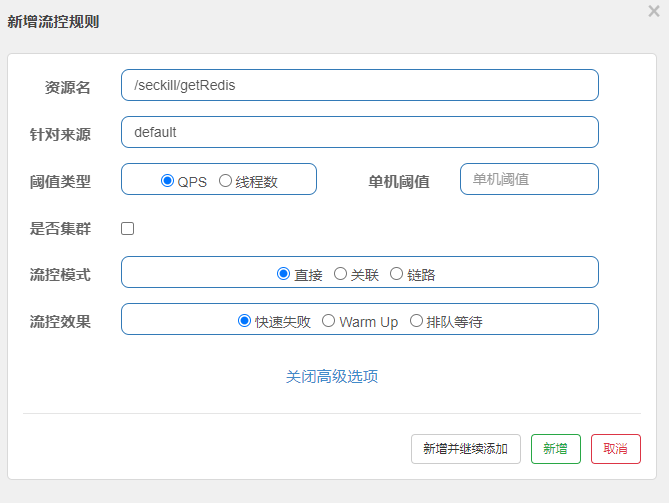
点击资源/seckill/getRedis后面的流控按钮,就可以弹出表单。

表单中可以填写限流规则,如下:
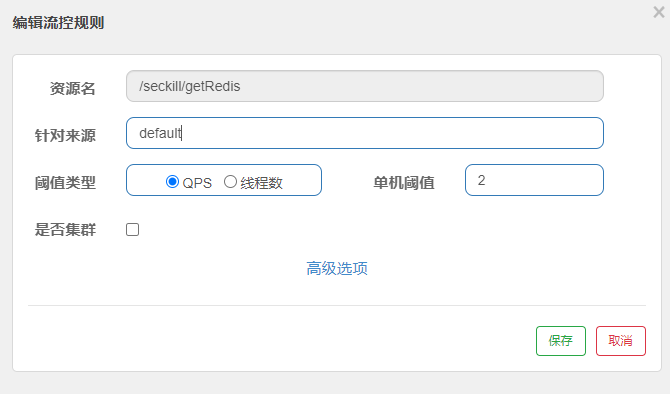
其含义是限制/seckill/getRedis这个资源的单机QPS为1,即每秒只允许2次请求,超出的请求会被拦截并报错。
2.1.2.练习:
需求:结合Jmeter(压测的小工具)测试给 /order/list这个资源设置流控规则,QPS不能超过 5,然后测试。
2.2.流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
- 直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
- 关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
- 链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
快速入门测试的就是直接模式。
2.2.1.关联模式
关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
配置规则:
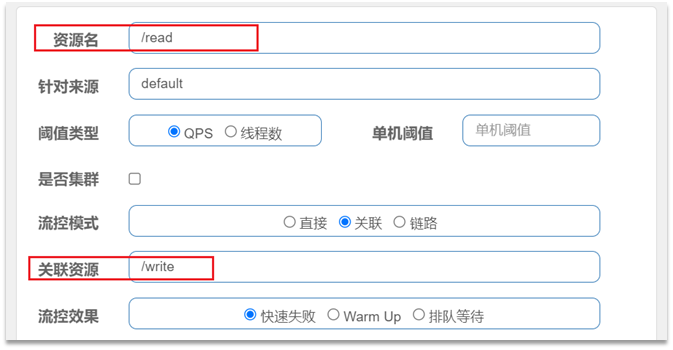
语法说明:当/write资源访问量触发阈值时,就会对/read资源限流,避免影响/write资源。
使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是优先支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
需求说明:
在Controller新建两个端点:query和/update,无需实现业务
配置流控规则,当/ update资源被访问的QPS超过5时,对/query请求限流
1)定义/query端点,模拟订单查询
1 |
|
2)定义/update端点,模拟订单更新
1 |
|
重启服务,查看sentinel控制台的簇点链路:
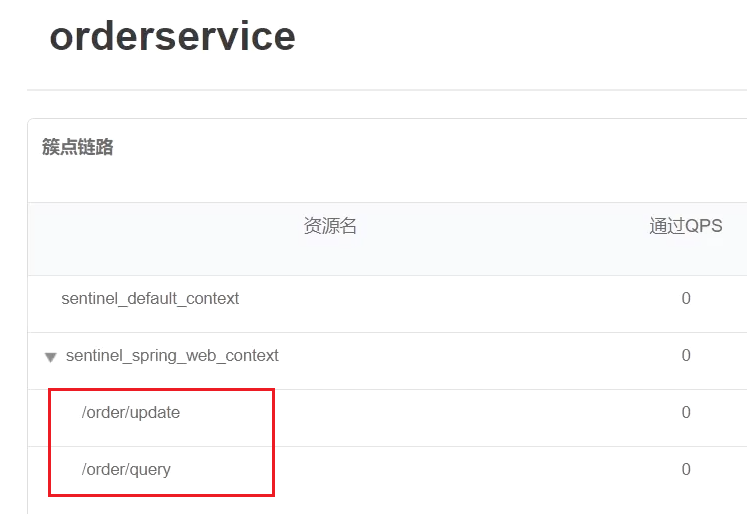
3)配置流控规则
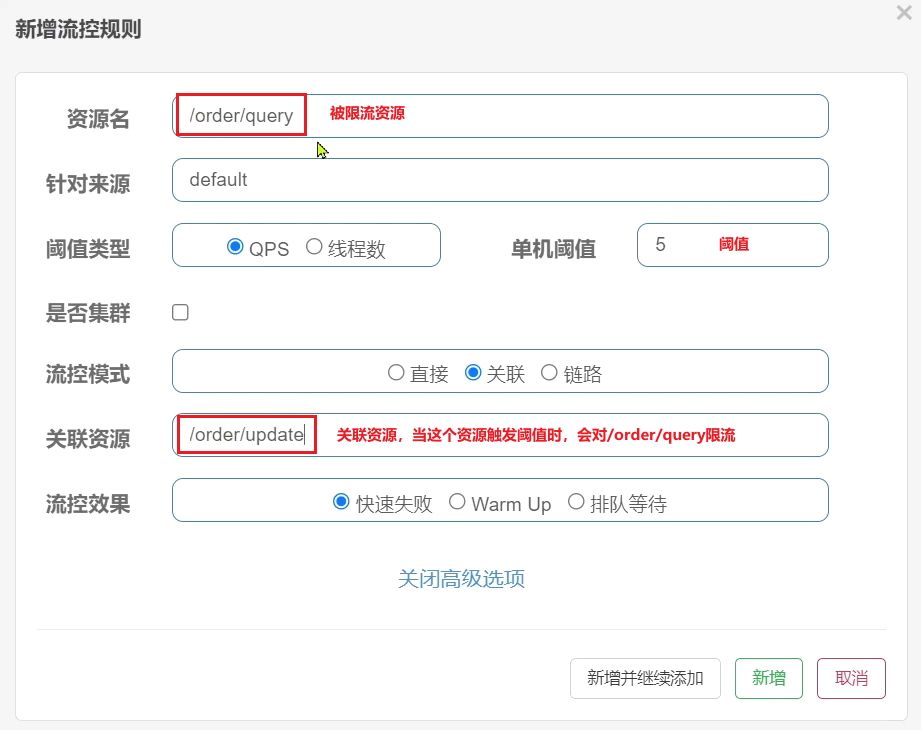
对哪个端点限流,就点击哪个端点后面的按钮。我们是对订单查询/order/query限流,因此点击它后面的按钮:

在表单中填写流控规则:
4)在Jmeter测试
选择《流控模式-关联》:
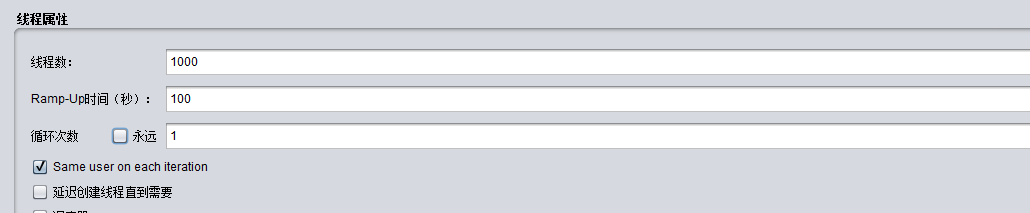
可以看到1000个用户,100秒,因此QPS为10,超过了我们设定的阈值:5
请求的目标是update,这样这个断点就会触发阈值。
但限流的目标是query,我们在浏览器访问,可以发现:

确实被限流了。
5)总结

2.2.2.链路模式
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
配置示例:
例如有两条请求链路:
/test1 –> /common
/test2 –> /common
如果只希望统计从/test2进入到/common的请求,则可以这样配置:
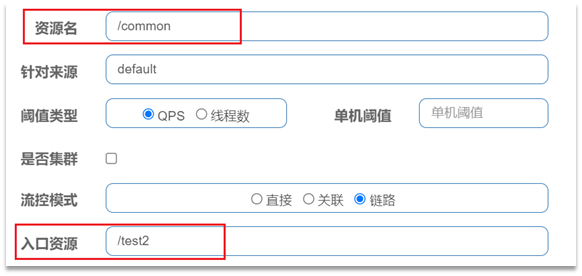
实战案例
需求:有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
实现:
1)添加查询商品方法
在order-service服务中,给OrderService类添加一个queryGoods方法:
1 | public void queryGoods(){ |
2)查询订单时,查询商品
在order-service的OrderController中,修改/order/query端点的业务逻辑:
1 |
|
3)新增订单,查询商品
在order-service的OrderController中,修改/order/save端点,模拟新增订单:
1 |
|
4)给查询商品添加资源标记
默认情况下,OrderService中的方法是不被Sentinel监控的,需要我们自己通过注解来标记要监控的方法。
给OrderService的queryGoods方法添加@SentinelResource注解:
1 |
|
修改配置
1 | spring: |
重启服务,访问/order/query和/order/save,可以查看到sentinel的簇点链路规则中,出现了新的资源:
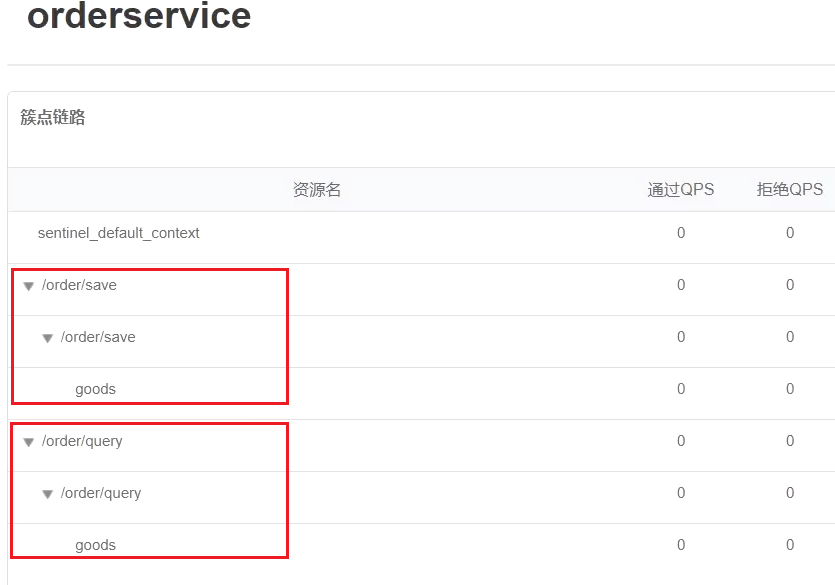
5)添加流控规则
点击goods资源后面的流控按钮,在弹出的表单中填写下面信息:
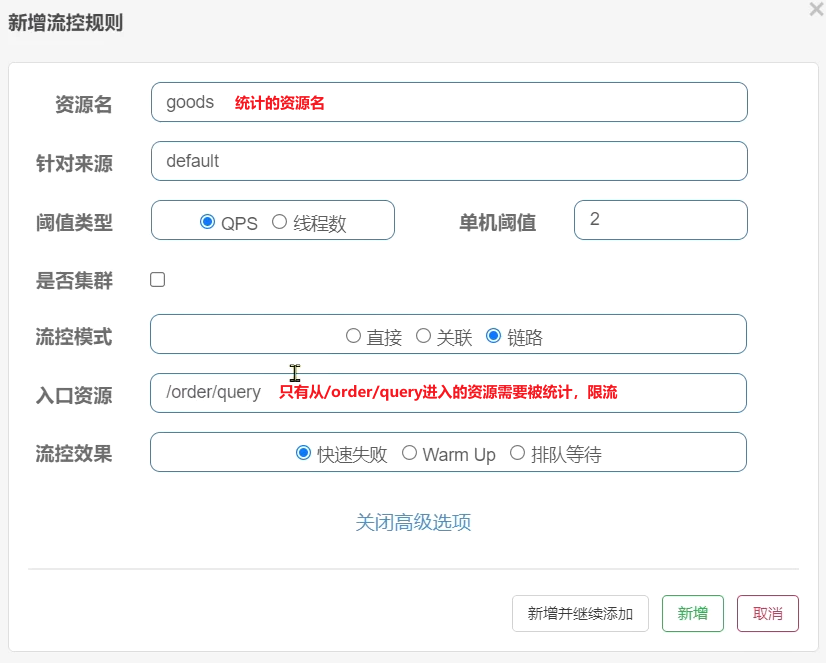
只统计从/order/query进入/goods的资源,QPS阈值为2,超出则被限流。
2.2.3.总结
流控模式有哪些?
•直接:对当前资源限流
•关联:高优先级资源触发阈值,对低优先级资源限流。
•链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
2.3.流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
2.3.1.warm up
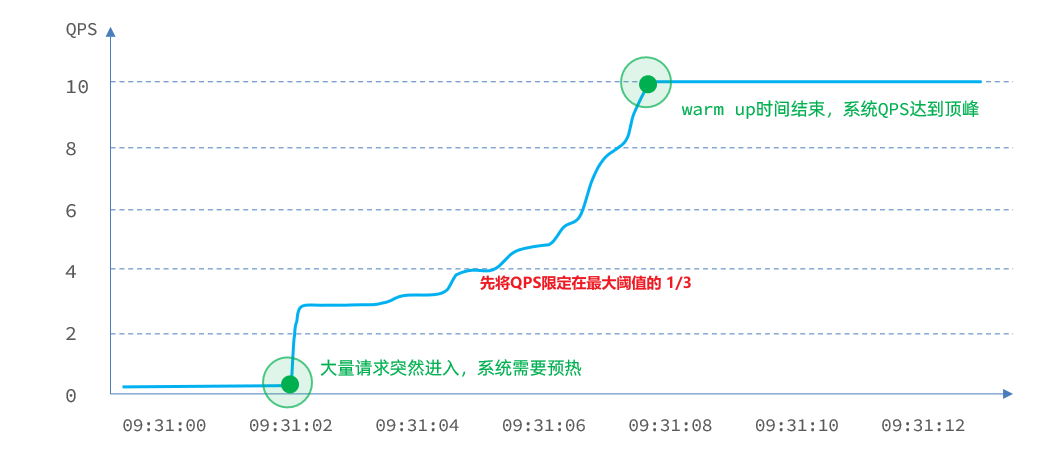
阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到最大值,可能导致服务瞬间宕机。
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 maxThreshold / coldFactor,持续指定时长后,逐渐提高到maxThreshold值。而coldFactor的默认值是3.
例如,我设置QPS的maxThreshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
案例
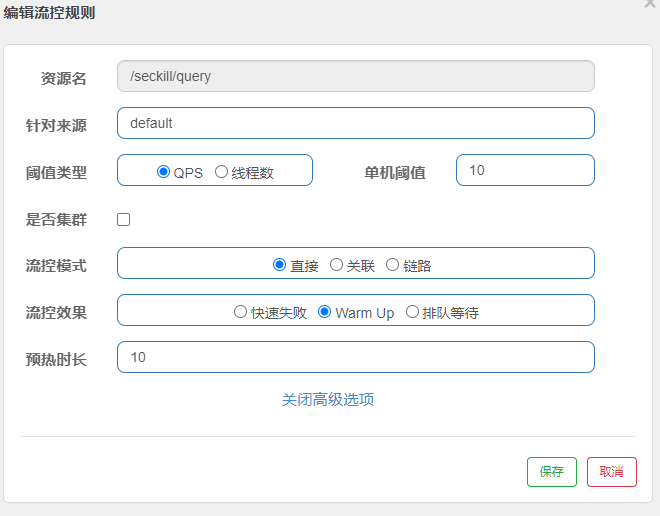
需求:给/seckill/query这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒
1)配置流控规则:
2.3.2.排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。
而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
工作原理
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
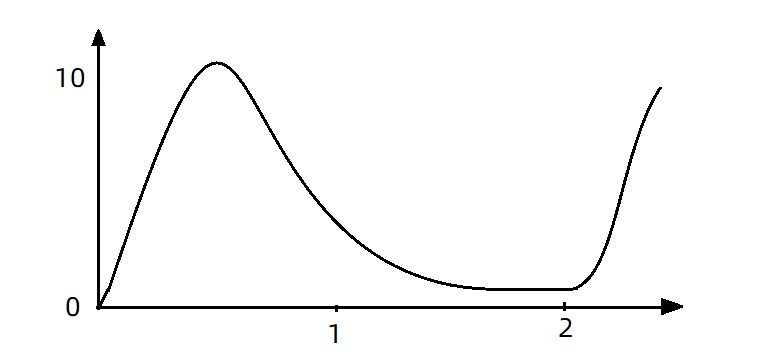
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
- 第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
- 第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
现在,第1秒同时接收到10个请求,但第2秒只有1个请求,此时QPS的曲线这样的:
如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑:
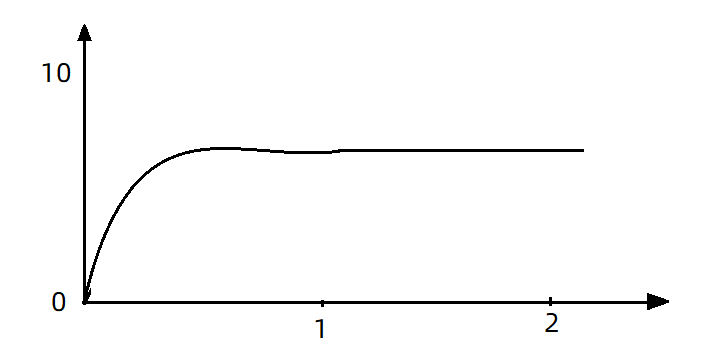
平滑的QPS曲线,对于服务器来说是更友好的。
案例
需求:给/seckill/query这个资源设置限流,最大QPS为10,利用排队的流控效果,超时时长设置为5s
2.3.3.总结
流控效果有哪些?
快速失败:QPS超过阈值时,拒绝新的请求
warm up: QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。
排队等待:请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝
3.隔离和降级
限流是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
线程隔离之前讲到过:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
可以看到,不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。需要在调用方 发起远程调用时做线程隔离、或者服务熔断。
而我们的微服务远程调用都是基于Feign来完成的,因此我们需要将Feign与Sentinel整合,在Feign里面实现线程隔离和服务熔断。
3.1.FeignClient整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
3.1.1.修改配置,开启sentinel功能
修改OrderService的application.yml文件,开启Feign的Sentinel功能:
1 | feign: |
3.1.2.编写失败降级逻辑
业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
这里我们演示方式二的失败降级处理。
步骤一:在feing-api项目中定义类,实现FallbackFactory:
代码:
1 |
|
步骤二:在feing-api项目中的FallbackConfig类中将SellerFallback注册为一个Bean:
1 |
|
步骤三:在feing-api项目中的SellerAPI接口中使用UserClientFallbackFactory:
1 |
|
重启后,访问一次秒杀商品查询业务,然后查看sentinel控制台,可以看到新的簇点链路:

3.1.3.总结
Sentinel支持的雪崩解决方案:
- 线程隔离(仓壁模式)
- 降级熔断
Feign整合Sentinel的步骤:
- 在application.yml中配置:feign.sentienl.enable=true
- 给FeignClient编写FallbackFactory并注册为Bean
- 将FallbackFactory配置到FeignClient
3.2.线程隔离(舱壁模式)
3.2.1.线程隔离的实现方式
线程隔离有两种方式实现:
- 线程池隔离
- 信号量隔离(Sentinel默认采用)
如图:
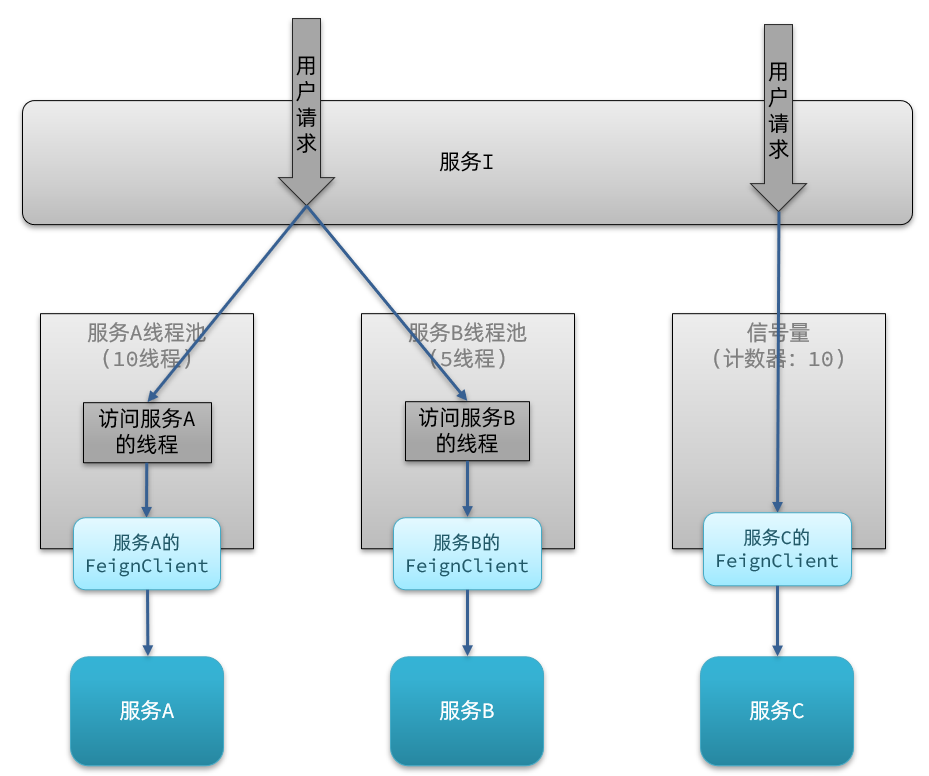
线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
两者的优缺点:

3.2.2.sentinel的线程隔离
用法说明:
在添加限流规则时,可以选择两种阈值类型:
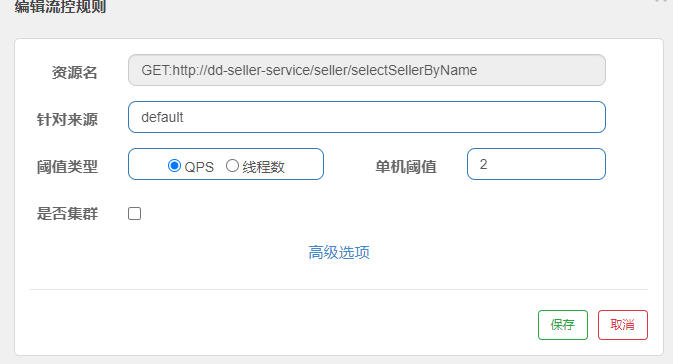
- QPS:就是每秒的请求数
- 线程数:是该资源能使用用的tomcat线程数的最大值。也就是通过限制线程数量,实现线程隔离(舱壁模式)。
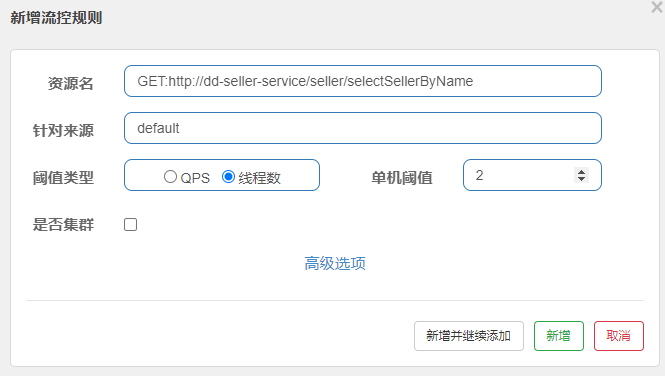
案例需求:给 秒杀服务服务中的SellerAPI的查询商户接口设置流控规则,线程数不能超过 2。然后利用jemeter测试。
1)配置隔离规则
选择feign接口后面的流控按钮:

填写表单:
3.2.3.总结
线程隔离的两种手段是?
- 信号量隔离
- 线程池隔离
信号量隔离的特点是?
- 基于计数器模式,简单,开销小
线程池隔离的特点是?
- 基于线程池模式,有额外开销,但隔离控制更强
3.3.熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
断路器控制熔断和放行是通过状态机来完成的:
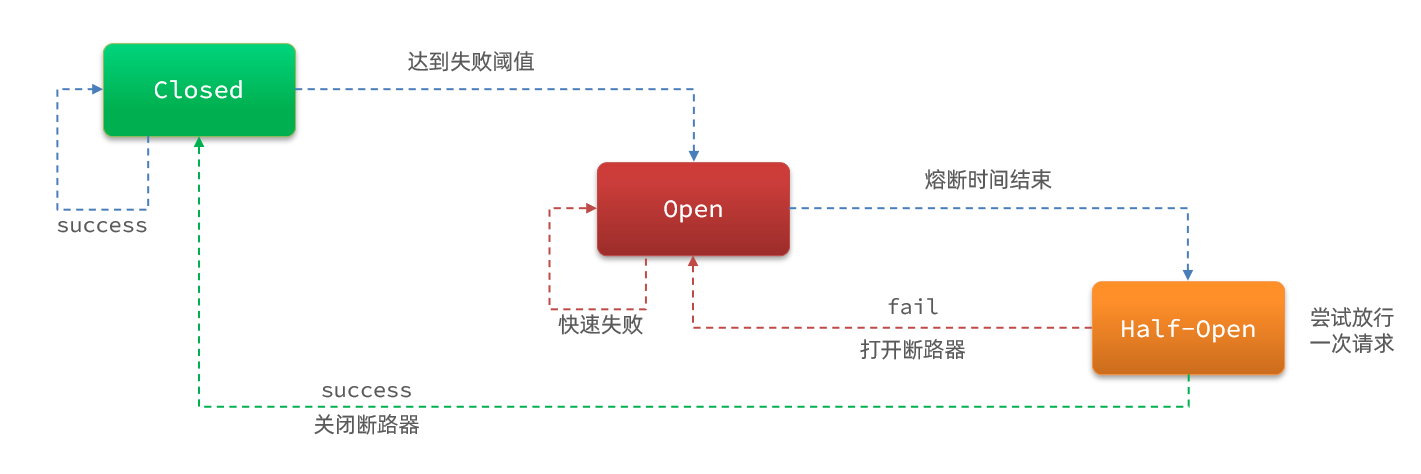
状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
- half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
断路器熔断策略有三种:慢调用、异常比例、异常数
3.3.1.慢调用
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。
例如:
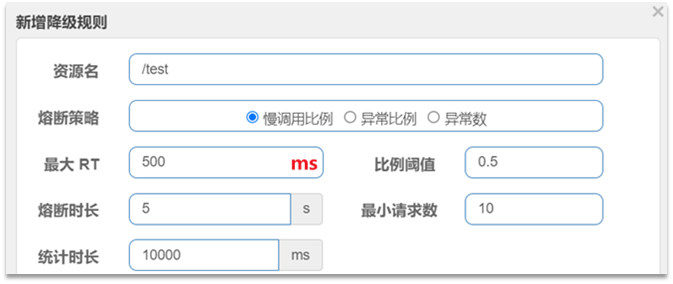
解读:RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
案例
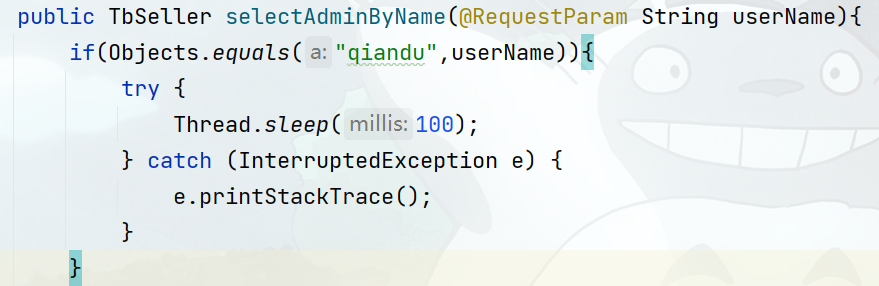
需求:给 seller-service的查询商家接口设置降级规则,慢调用的RT阈值为50ms,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5
1)设置慢调用
修改seller-service中的查询商户这个接口的业务。通过休眠模拟一个延迟时间:
2)设置熔断规则
下面,给feign接口设置降级规则:

规则:
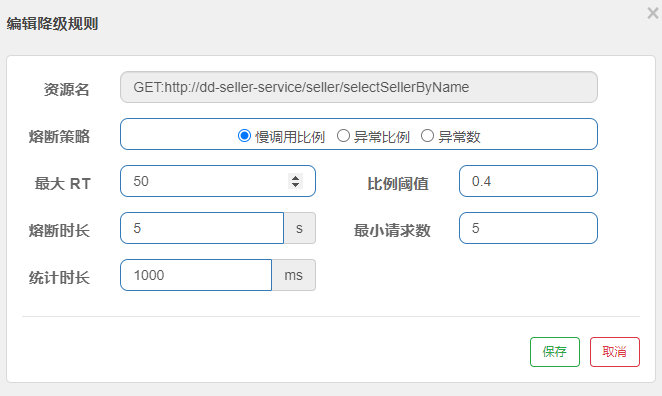
超过50ms的请求都会被认为是慢请求
3)测试
在浏览器访问:http://localhost:10011/seckill/queryById?goodId=1,快速刷新5次,可以发现:
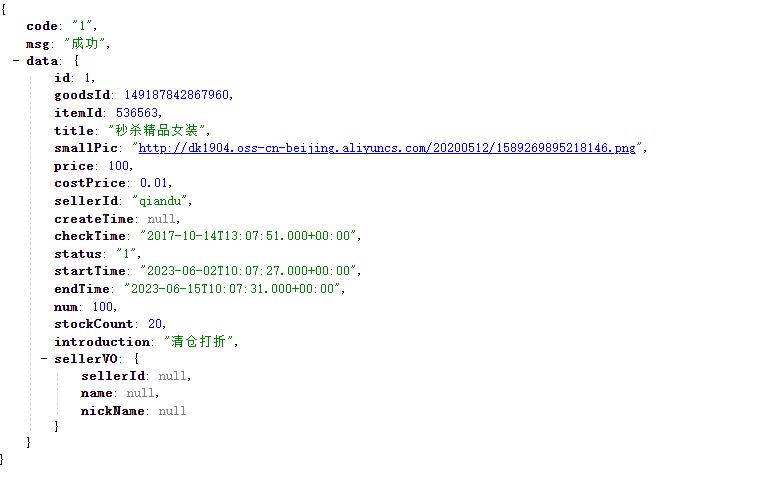
触发了熔断,请求时长缩短,快速失败了,并且走降级逻辑,返回的null
在浏览器访问:http://localhost:10011/seckill/queryById?goodId=2,竟然也被熔断了:
因为已经触发熔断,断路器生效,需要5秒后才能正常访问该服务
3.3.2.异常比例、异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
例如,一个异常比例设置:
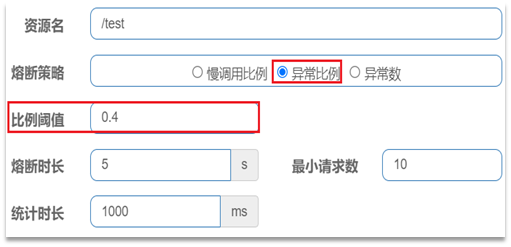
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断。
一个异常数设置:
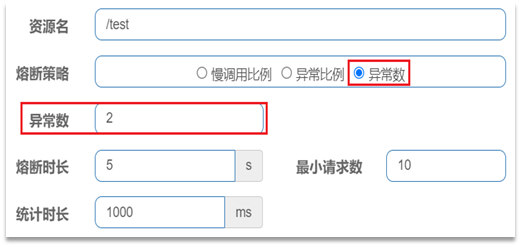
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于2次,则触发熔断。
案例
需求:给 seller-service的查询商户接口设置降级规则,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5s
1)设置异常请求
首先,修改seller-service中的查询商户这个接口的业务。手动抛出异常,以触发异常比例的熔断:
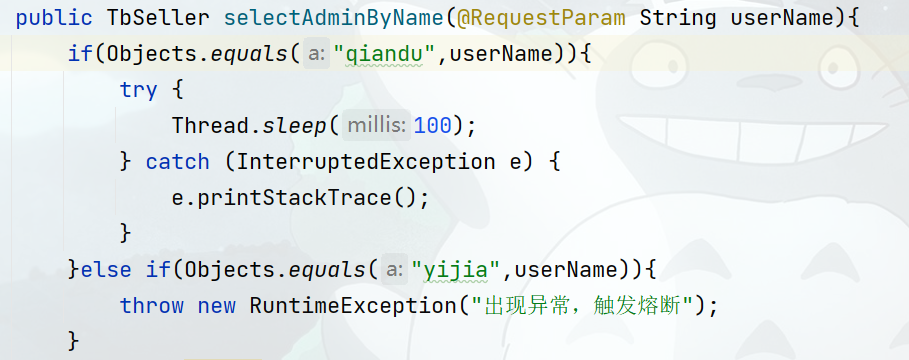
也就是说,id 为 2时,就会触发异常
2)设置熔断规则
规则:
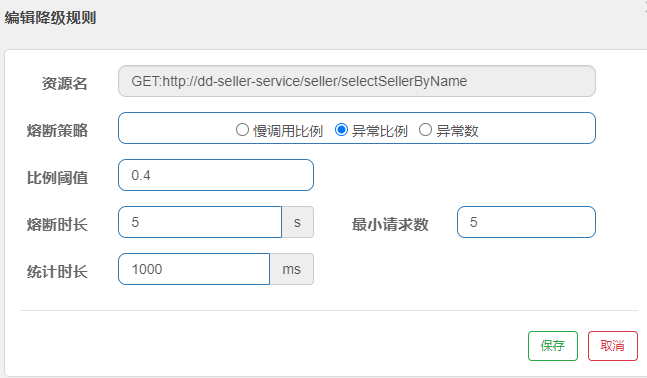
在5次请求中,只要异常比例超过0.4,也就是有2次以上的异常,就会触发熔断。
3)测试
在浏览器快速访问:http://localhost:10011/seckill/queryById?goodId=2,快速刷新5次,触发熔断:
此时,我们去访问本来应该正常的http://localhost:10011/seckill/queryById?goodId=3: