2. 整型在内存 中的存储 2.1 原码、反码、补码
计算机中的整数有三种表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位负整数的三种表示方法各不相同。
原码
反码
补码
注意:
(1)正数的原、反、补码都相同。 (2)对于整形来说:数据存放内存中其实存放的是补码。那么为什么呢?
总结而言,有两点原因:一是为了进行负数的有关运算;二是为了提高运算的效率。
2.2 大小端介绍 2.2.1 什么是大小端
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址 中。
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地 址中。
下面是图解:
注意:大小端只是针对字节的,对于仅有一个字节的char类型来说,无所谓大小端,即不谈大小端。
2.2.2为什么有大端和小端? 下面的内容了解即可:
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节 ,那么必然存在着一个如何将多个字节安排的问题 。因此就导致了大端存储模式和小端存储模式 。 例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为 高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
3. 浮点型在内存中的存储 3.1例题引入 思考下面程序的输出结果,并且想一下为什么会出现这种结果。
3.2 浮点数存储规则
根据国际标准IEEE(电气和电子工程协会) 754:
任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
那么,按照上面的格式,可以得出s=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,s=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。
对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
此外:IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。 IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。比如保存1.01的时 候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位 浮点数为例,留给M只有23位, 将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。 首先,E为一个无符号整数(unsigned int) 这意味着,如果E为8位,它的取值范围为0255;如果E为11位,它的取值范围为02047。但是,我们 知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,**对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。**比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
然后,指数E从内存中取出还可以再分成三种情况:
(1)E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将 有效数字M前加上第一位的1。 比如: 0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:
0 01111110 00000000000000000000000
(2)E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示**±0,以及接近于0的很小的数字**。
注意:这个地方为什么不是0-127呢?这是规定!规定就是把E全为0的时候看作是1-127即-126。
(3)E全为1
这时,如果有效数字M全为0,表示**±无穷大**(正负取决于符号位s)。
到了这里,前面的题目就显而易见了,因为上面是以浮点数形式进行打印,就是将二进制的数字看成是浮点数,即按照浮点数在内存中存储的形式进行打印。
将9.0存入*pFloat中时,先将9.0按照浮点数的形式存储起来,就是按照上面的格式,按照整数的形式进行打印的时候自然就会出现一个比较大的数字。
1、C语言中是否存在字符串?
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串中或者字符数组中。 字符串常量适用于那些对它不做修改的字符串函数!
2、函数介绍 2.1 strlen()
strlen()函数的作用是求字符串的长度。
2.1.1模拟实现strlen()(三种方法实现) (1)计数器方法
1 2 3 4 5 6 7 8 9 10 11 12 #include <assert.h> int my_strlen (const char * str) { assert(str != NULL ); int count = 0 ; while (*str != '\0' ) { count++; str++; } return count; }
(2)递归实现(不定义临时变量的方法)
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> int my_strlen (const char * str) { if (*str != '\0' ) { return 1 +my_strlen(++str); } else { return 0 ; } }
(3)尾指针-头指针
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <assert.h> int my_strlen (const char * str) { const char * ret = NULL ; assert(*str != NULL ); ret = str; while (*ret != "\0" ) { ret++; } return ret - str; }
2.1.2 注意点 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> #include <string.h> int main () { const char * str1 = "abcdef" ; const char * str2 = "bbb" ; if (strlen (str2) - strlen (str1) > 0 ) { printf ("str2>str1\n" ); } else { printf ("srt1>str2\n" ); } return 0 ; }
运行截图:
原因:
strlen()函数的返回类型是size_t即unsigned int类型,在操作符两侧的数据类型都是unsigned int ,运算结果类型也必然是unsigned int,这个值永远是大于0的,所以会出现上面的结果!
结论
自己实现的时候将返回类型写成size_t和int各有利弊。
int可以有效的应对上面的这种特殊情况,但是不容易理解,因为int包括负数。
size_t更容易理解,但是无法有效的应对像上面的这种情况。
2.1.3 strlen()函数介绍
(1)字符串以 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前面出现的字符个数(不包 含 ‘\0’ )。
(2)参数指向的字符串必须要以 ‘\0’ 结束。
(3)注意函数的返回值为size_t,是无符号的( 易错 )
2.2 strcpy()
strcpy()函数的作用是将一个字符串的内容拷贝到另一个字符串中去(包括’\0’)。
2.2.1模拟实现strcpy() 1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <assert.h> char * my_strcpy (char * dest, const char * src) { assert(dest != NULL ); assert(src != NULL ); char * ret = dest; while (*dest++ = *src++) {} return ret; }
2.2.2 注意事项
(1)源字符串必须以’\0’结束,比如源字符串像这样定义的就无法正常拷贝了:
char src[] = {‘m’,’i’,’n’};
(2)要将’\0’拷贝到目标空间
(3)目标空间必须足够大,以确保能存放源字符串
(4)目标空间必须可变,比如目标字符串这样定义就不行了:
char *dest = “abcde”;
因为此时的目标字符串所存放的空间是在字符串常量区,此处的字符串是无法进行修改的,此时程序会崩溃。
strcpy()的作用是追加字符串。
2.3.1 模拟实现strcat() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <assert.h> char * my_strcat (char * str1, const char * str2) { assert(str1&&str2); char * ret = str1; while (*str1 != '\0' ) { str1++; } while (*str1++ = *str2++) { ; } return ret; }
2.3.2 注意事项
(1)源字符串必须以’\0’结束
(2)目标空间必须有足够大的空间能容纳下源字符串的内容
(3)目标空间必须可修改
(4)不能自己给自己追加,那样程序会崩溃。
比较对应字符对应的ASCII码值的大小,而不是比较字符串的长度,逐个字符进行比较,如果所有字符都相同就返回一个等于0的数组,如果前面的小于后面的,就返回一个小于0的数字,大于后面的就返回一个大于0的数字。
2.4.1 模拟实现strcmp() 下面是VS2019的模拟实现方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <stdio.h> #include <assert.h> int my_strcmp (const char * str1, const char * str2) { assert(str1 && str2); while (*str1 == *str2) { if (*str1 == '\0' ) { return 0 ; } str1++; str2++; } if (*str1 > *str2) { return 1 ; } else { return -1 ; } } int main () { char *str1 = "abcde" ; char *str2 = "abcfg" ; int ret = my_strcmp(str1, str2); printf ("%d" , ret); return 0 ; }
下面是linux的模拟实现方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <assert.h> int my_strcmp (const char * str1, const char * str2) { assert(str1 && str2); while (*str1 == *str2) { if (*str1 == '\0' ) { return 0 ; } str1++; str2++; } return (*str1-*str2); } int main () { char *str1 = "abcde" ; char *str2 = "abcfg" ; int ret = my_strcmp(str1, str2); printf ("%d" , ret); return 0 ; }
2.4.2 注意事项 标准规定
(1)第一个字符串大于第二个字符串,则返回大于0的数字
(2)第一个字符串等于第二个字符串,则返回0
(3)第一个字符串小于第二个字符串,则返回小于0的数字
注意
strcpy(),strcat(),strcmp()都是与长度无关的字符串函数,相对来说不是那么的安全,只受’\0’的限制。
2.5.1 strncpy()的模拟实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <assert.h> char * my_strncpy (char * str1, const char * str2,int count) { assert(str1 && str2); char * ret = str1; int i = 0 ; for (i = 0 ; i < count; i++) { if (*str2 != '\0' ) { *str1++ = *str2++; } else { *str1++ = '\0' ; } } return ret; }
2.5.2 注意事项
(1)拷贝num个字符从源字符串到目标空间。
(2)如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
2.6 strncat() 2.6.1 模拟实现strncat() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <assert.h> char * my_strncat (char * str1, const char * str2, int count) { assert(str1 && str2); char * ret = str1; while (*str1++ != '\0' ); str1--; int i = 0 ; for (i = 0 ; i < count; i++) { if (*str2 != '\0' ) { *str1++ = *str2++; } else { *str1 = '\0' ; return ret; } } *str1 = '\0' ; return ret; }
2.7 strncmp() 2.7.1 模拟实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <assert.h> int my_strncmp (const char * str1, const char * str2, int count) { assert(str1 && str2); int i = 0 ; for (i = 0 ; i < count; i++) { if (*str1 < *str2) { return -1 ; } else if (*str1 > *str2) { return 1 ; } else { str1++; str2++; } } return 0 ; }
2.8 strstr()
注意:在读文档时出现NULL一般就是空指针,NUL或者Null就是’\0’。
2.8.1 使用说明及示例
(1)前面是被查找的字符串,后面是要查找的字符串。
(2)如果能够找到,就返回后面的字符串在前面字符串中首次出现的地址,如果未出现,就返回空指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <string.h> int main () { char * str1 = "abcdefghijk" ; char * str2 = "def" ; char *ret = strstr (str1, str2); if (ret == NULL ) { printf ("字串不存在\n" ); } else { printf ("%s\n" ,ret); } return 0 ; }
运行截图:
2.8.2 模拟实现strstr() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <stdio.h> #include <assert.h> char * my_strstr (const char * str1,const char * str2) { assert(str1 && str2); char * p1 = NULL ; char * p2 = NULL ; char * cur = str1; if (*str2 == '\0' ) { return (char *)str1; } while (*cur) { p1 = cur; p2 = (char *)str2; while ((*p1 != '\0' ) && (*p2 != '\0' ) && *p1 == *p2) { p1++; p2++; } if (*p2 == '\0' ) { return cur; } if (*p1=='\0' ) { return NULL ; } cur++; } return NULL ; }
2.9 strtok() 2.9.1 使用说明及示例
char * strtok ( char * str, const char * sep );
(1)sep参数是个字符串,定义了用作分隔符的字符集合
(2)第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标 记。
(3)strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注: strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容 并且可修改。)
(4)strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串 中的位置。
(5)strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标 记。
(6)如果字符串中不存在更多的标记,则返回 NULL 指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <string.h> int main () { char * arr = "123@456@abc.def.com" ; char * p = "@." ; char str[500 ] = { 0 }; strcpy (str, arr); char * ret = NULL ; for (ret = strtok(str, p);ret != NULL ;ret = strtok(NULL ,p)) { printf ("%s\n" , ret); } return 0 ; }
运行截图:
2.10 strerror() 2.10.1 使用说明及示例
返回错误码,所对应的错误信息。
示例:
1 2 3 4 5 6 7 8 #include <stdio.h> #include <string.h> int main () { char * str0 = strerror(0 ); printf ("%s\n" , str0); return 0 ; }
运行截图:
0:No error
1:Operation not permitted
2:No such file or directory
3:No such process
……
下面是较为完整的用法:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> #include <errno.h> #include <string.h> int main () { char * str = strerror(errno); printf ("%s\n" , str); return 0 ; }
2.11 其它函数 2.11.1 字符分类函数 注意引头文件<ctype,h>
函数
如果他的参数符合下列条件就返回真
iscntrl
任何控制字符
isspace
空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v'
isdigit
十进制数字 0~9
isxdigit
十六进制 数字,包括所有十进制数字,小写字母a~f,大写字母A~F
islower
小写字母a~z
isupper
大写字母A~Z
isalpha
字母a~z或A~Z
isalnum
字母或者数字,a~z,A~Z,0~9
ispunct
标点符号,任何不属于数字或者字母的图形字符(可打印)
isgraph
任何图形字符
isprint
任何可打印字符,包括图形字符和空白字符
判定结果为是的话返回一个非零值,如果不是返回一个零值。
2.11.2 字符转换函数 1 2 int tolower ( int c ) ;int toupper ( int c ) ;
注意:只能一个字符一个字符的进行转换,不能一次转换一个字符串!
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <ctype.h> int main () { int i = 0 ; char str[] = "Test String.\n" ; char c; while (str[i]) { c = str[i]; if (isupper (c)) c = tolower (c); putchar (c); i++; } return 0 ; }
运行截图:
3. 内存函数 3.1 memcpy() 3.1.1 使用说明及示例 说明
(1)函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
(2)这个函数在遇到 ‘\0’ 的时候并不会停下来。
(3)如果source和destination有任何的重叠,复制的结果都是未定义的 。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <string.h> int main () { int arr1[] = { 1 ,2 ,3 ,4 ,5 }; int arr2[5 ] = {0 }; memcpy (arr2, arr1, sizeof (arr1)); for (int i = 0 ; i < 5 ; i++) { printf ("%d " , arr2[i]); } return 0 ; }
3.1.2 模拟实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <assert.h> void *my_memcpy (void * dest, const void * src, size_t num) { assert(dest && src); void * ret = dest; int i = 0 ; while (num--) { *(char *)dest = *(char *)src; ((char *)dest)++; ((char *)src)++; } return dest; }
3.2 memmove() 3.2.1 使用说明及示例
(1)和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
(2)如果源空间和目标空间出现重叠,就得使用memmove函数处理。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <string.h> int main () { int arr[] = { 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 }; memmove(arr + 2 , arr, 20 ); for (int i = 0 ; i < 10 ; i++) { printf ("%d " , arr[i]); } return 0 ; }
C语言标准:
memcpy()只要能处理不重叠的内存拷贝就可以了。
memmove处理重叠内存的拷贝。
3.2.2 模拟实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> #include <assert.h> void *my_memmove (void * dest, void * src, size_t num) { assert(dest && src); void * ret = dest; if (dest < src) { while (num--) { *(char *)dest = *(char *)src; ((char *)dest)++; ((char *)src)++; } } else { while (num--) { *((char *)dest+num )= *((char *)src+num); } } return dest; }
3.3 memcmp() 3.3.1 使用说明及示例 1 int memcmp ( const void * ptr1, const void * ptr2, size_t num ) ;
示例:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> #include <string.h> int main () { int arr1[] = { 1 ,2 ,3 ,4 ,5 }; int arr2[] = { 1 ,2 ,4 ,5 ,6 }; int ret = memcmp (arr1, arr2, sizeof (arr1)); printf ("%d" , ret); return 0 ; }
3.4 memset() 3.4.1 使用说明及示例 1 void * memset (void * dest, int c, size_t count) ;
作用:设置缓冲区为一个特定的字符。
dest:目的地空间的起始位置。
c:要设定的字符(无论c是都看成字符)。
count:要设定字符的数目(注意是字符的数目。此处都是以字节为单位的,因为一个字符所占的内存空间是一个字节)
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <string.h> int main () { char arr[10 ] = "" ; memset (arr, '#' , 10 ); for (int i = 0 ; i < 10 ; i++) { printf ("%c " , arr[i]); } return 0 ; }
运行截图:
在指针的类型中我们知道有一种指针类型为字符指针 char*
一般使用:
1 2 3 4 5 6 7 int main () { char ch = 'w' ; char * pc = &ch; *pc = 'w' ; return 0 ; }
还有一种使用方式如下:
1 2 3 4 5 6 int main () { const char * pstr = "hello bit." ; printf ("%s\n" , pstr); return 0 ; }
代码 const char* pstr = “hello bit.”;
特别容易让同学以为是把字符串 hello bit 放到字符指针 pstr 里了,但是本质上是把字符串 hello bit. 首字符的地址放到了pstr中。
上面代码的意思是把一个常量字符串的首字符 h 的地址存放到指针变量 pstr 中。
那就有可这样的面试题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> int main () { char str1[] = "hello bit." ; char str2[] = "hello bit." ; const char * str3 = "hello bit." ; const char * str4 = "hello bit." ; if (str1 == str2) printf ("str1 and str2 are same\n" ); else printf ("str1 and str2 are not same\n" ); if (str3 == str4) printf ("str3 and str4 are same\n" ); else printf ("str3 and str4 are not same\n" ); return 0 ; }
问:上述代码的输出结果是什么?
这里str3和str4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区域,当 几个指针。指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始化 不同的数组的时候就会开辟出不同的内存块。所以str1和str2不同,str3和str4相同。
其实呢,关于指针数组的相关知识,我们在前面的学习中已经了解到了,今天呢,再带大家来了解一下,并且懂得指针数组的相关的使用!
指针数组:存放指针的数组,即数组的每一个元素都是指针 。下面简单介绍一下其用法!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> int main () { int arr1[] = { 1 ,2 ,3 ,4 ,5 }; int arr2[] = { 2 ,3 ,4 ,5 ,6 }; int arr3[] = { 3 ,4 ,5 ,6 ,7 }; int * arr[] = { arr1,arr2,arr3 }; for (int i = 0 ; i < 3 ; i++) { for (int j = 0 ; j < 5 ; j++) { printf ("%d " , *(arr[i] + j)); } printf ("\n" ); } return 0 ; }
通过上面的这种方法可以实现遍历数组的元素!当然,其实这也是二维数组的本质所在,后面还会进行相关的讲解,相信大家在后面会对这些有一个更深入的理解,此处只是起到一个抛砖引玉的作用!
3.1数组指针的定义
数组指针是指针?还是数组?
答案是:指针。
我们已经熟悉:
整形指针: int * pint; 能够指向整形数据的指针。
浮点型指针: float * pf; 能够指向浮点型数据的指针。
那数组指针应该是:能够指向数组的指针。 下面代码哪个是数组指针?
1 2 3 int *p1[10 ];int (*p2)[10 ];
解释:
1 2 3 4 int *p1[10 ];int (*p)[10 ];
3.2 &数组名VS数组名
对于下面的数组:
arr 和 &arr 分别是啥?
我们知道arr是数组名,数组名表示数组首元素的地址。 那&arr数组名到底是啥?
我们看一段代码:
1 2 3 4 5 6 7 8 #include <stdio.h> int main () { int arr[10 ] = { 0 }; printf ("%p\n" , arr); printf ("%p\n" , &arr); return 0 ; }
运行截图:
可见数组名和&数组名打印的地址是一样的。
难道两个是一样的吗? 我们再看一段代码:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main () { int arr[10 ] = { 0 }; printf ("arr = %p\n" , arr); printf ("&arr= %p\n" , &arr); printf ("arr+1 = %p\n" , arr + 1 ); printf ("&arr+1= %p\n" , &arr + 1 ); return 0 ; }
运行截图:
根据上面的代码我们发现,其实&arr和arr,虽然值是一样的,但是意义应该不一样的。
实际上: &arr 表示的是数组的地址 ,而不是数组首元素的地址。
本例中 &arr 的类型是: int(*)[10] ,是一种数组指针类型 数组的地址+1,跳过整个数组的大小,所以 &arr+1 相对于 &arr 的差值是40
3.3 数组指针的使用
那数组指针是怎么使用的呢?
既然数组指针指向的是数组,那数组指针中存放的应该是数组的地址。
看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> int main () { int arr[10 ] = { 1 ,2 ,3 ,4 ,5 }; int (*ptr)[10 ] = &arr; for (int i = 0 ; i < 5 ; i++) { printf ("%d " , *((*ptr) + i)); } return 0 ; }
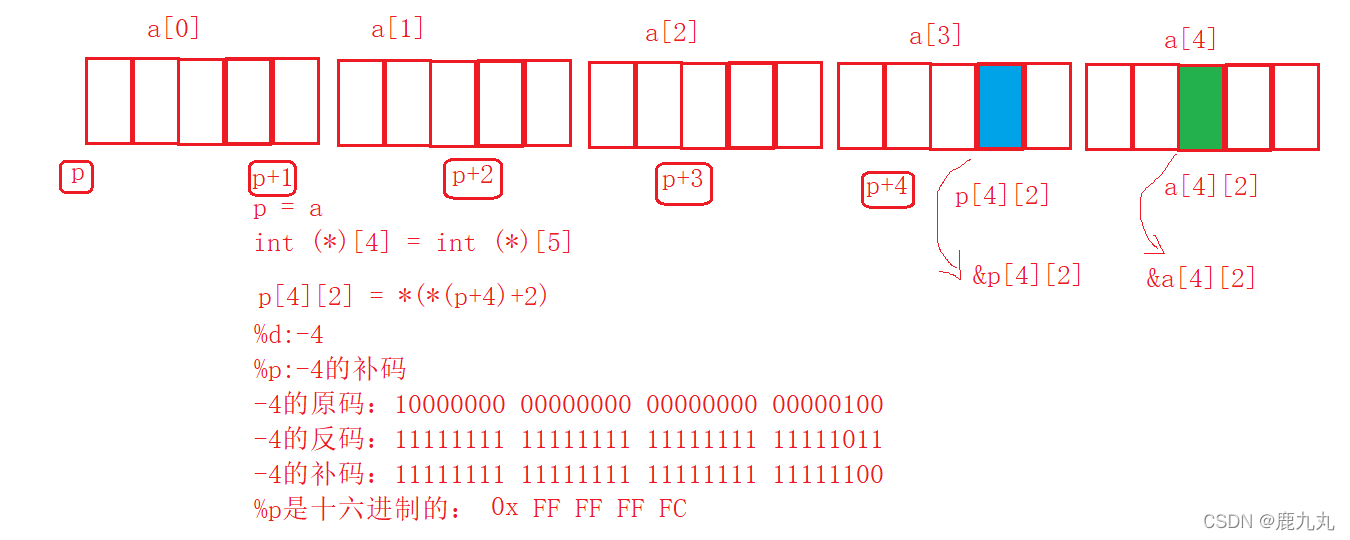
当然,上面的运用只是一种简单的运用,下面结合二维数组来给大家进行展示一下相关的运用!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> void print (int (*p)[5 ], int x, int y) { for (int i = 0 ; i < x; i++) { for (int j = 0 ; j < y; j++) { printf ("%d " , *(*(p + i) + j)); } printf ("\n" ); } } int main () { int arr[3 ][5 ] = { {1 ,2 ,3 ,4 ,5 },{2 ,3 ,4 ,5 ,6 },{3 ,4 ,5 ,6 ,7 } }; print(arr, 3 , 5 ); return 0 ; }
大家应该会觉得相对来说不太好理解,下面我将简单给大家进行解释一下!
问题1:为什么在print函数的形参会是数组指针的形式?
答:因为数组名代表首元素的地址,我们都知道,整型的一维数组的元素是整型,实际上我们在求数组元素类型时常常会发生类似降维一样的情况,即此处由一维降到了点,那么我们来进行类推,二维数组也应该降成一维数组,而数组名我们在前面已经了解到了就是首元素的地址,而数组的地址的类型就是数组指针!
总结:我们在看待二维数组的时候,要把它看成是由一维数组组成的,即二维数组的每个元素就是一维数组,我们在将这个结论扩展到多维时也同样适用,比如三维数组的元素就是二维数组,四维数组的元素就是三维数组,那么其数组名的意义我们就相应的能够了解到了,
问题2:为什么上面的四种形式能够进行互换?
答:首先大家先看第一个为什么行,p代表的是第一行,p+i就是第i行,我们对其进行解引用,就是拿到的是这一行的元素,实际上在此处就是代表的是一维数组的数组名,而数组名又是数组的首地址,将其加上i后就是一维数组第i个元素的地址,再对其进行解引用,我们就得到了第i行第j列的元素。
为了帮助大家理解上面的等价替换,下面会给大家举个例子!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> int main () { int arr[10 ] = { 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 }; int * p = arr; for (int i = 0 ; i < 10 ; i++) { printf ("%d " , p[i]); } return 0 ; }
p[i] == arr[i] == *(p+i) == *(arr + i)
上面的四种形式其实是等效的!
下面我们进行类比一下,其实我们就能明白上面的四种形式为什么会相同!
*(*(p + i) + j)) == (*(p + i))[j]) == p[i][j]) == *(p[i]+j))
其实这个地方也不难,只是由一维扩展到了二维!
4. 数组参数、指针参数 在写代码的时候难免要把【数组】或者【指针】传给函数,那函数的参数该如何设计呢?
4.1 一维传参 4.1.1. 一维数组传参
一维数组传参有三种方法,下面给大家列举出来
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> void print (int arr[5 ]) { } int main () { int arr[5 ] = { 1 ,2 ,3 ,4 ,5 }; print(arr); return 0 ; }
注意:其实这三种传参方式本身并没有什么区别,其实无论是上面的哪一种方式进行传参,其本质上都是通过指针的方法进行传参,就像方法二一样,所以在方法一中的数字,写什么都是可以的,并没有任何的问题,在后续的使用上也并没有任何的区别。
4.1.2 一维指针数组传参 1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> void print (int * arr[5 ]) { } int main () { int * arr[5 ]; print(arr); return 0 ; }
4.2 二维数组传参 1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> void print (int arr[2 ][3 ]) { } int main () { int arr[2 ][3 ] = { {1 ,2 ,3 },{4 ,5 ,6 } }; print(arr); return 0 ; }
4.3 一级指针传参 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> void print (int * p, int sz) { int i = 0 ; for (i = 0 ; i < sz; i++) { printf ("%d\n" , *(p + i)); } } int main () { int arr[10 ] = { 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; int * p = arr; int sz = sizeof (arr) / sizeof (arr[0 ]); print(p, sz); return 0 ; }
思考:
当一个函数的参数部分为一级指针的时候,函数能接收什么参数?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void test1 (int * p) {} void test2 (char * p) {}
4.4 二级指针传参 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> void print (int ** pp) { } int main () { int a = 10 ; int * p = &a; int ** pp = &p; print(&p); print(pp); return 0 ; }
思考:
当函数的参数为二级指针的时候,可以接收什么参数?
首先可以比较清楚的了解到上面的这两种传参方式肯定是没有问题的,但是除了上面这两种之外还有别的传参方式!
1 2 3 4 5 6 7 8 9 10 11 12 13 #include<stdio.h> void print(int** pp) { } int main() { int* p[5]; print(p); //p是指针数组,数组的每一个元素都是指针,而我们传的是指针数组的数组名,即指针数组的首元素的地址 //指针数组的数组的首元素的地址即指针的地址,其类型就是二级指针 return 0; }
5. 函数指针
首先看一段代码:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> void test () { printf ("hehe\n" ); } int main () { printf ("%p\n" , test); printf ("%p\n" , &test); return 0 ; }
下面是程序的运行结果:
输出的是两个地址,这两个地址是 test 函数的地址。
这个地方相信大家就会想问了,那么这两个代表的意义时候完全相同呢?还是说像数组一样,数组名和&数组名代表不同的含义呢,这个地方就给大家说明白,函数名和&函数名代表着相同的含义,表示的都是函数的地址,其数值表现形式也都是函数的地址,两者没有任何的区别,在使用上也没有任何的区别 !
那我们的函数的地址要想保存起来,怎么保存?
下面我们看代码:
1 2 3 4 5 6 7 void test () { printf ("hehe\n" ); } void (*pfun1)();void * pfun2 () ;
首先,能给存储地址,就要求pfun1或者pfun2是指针,那哪个是指针?
答案是:
pfun1可以存放。pfun1先和*结合,说明pfun1是指针,指针指向的是一个函数,指向的函数无参数,返回值类型为void。
在这个地方相信大家还是不怎么理解,这里给大家进行解释一下,我们知道,对于数组来说,我们把在函数定义时的语句的变量名去掉就能得到定义的变量的类型,对于pfun1来说,我们将变量名去掉后,剩余的部分是void (*)(),如果我们将pfun2去掉之后,剩余的部分是 void *pfun()。
好像这两个乍一看并没有太大的区别,在它们进行定义时的唯一的区别就是pfun1比pfun2多了一个(),我们清楚,()的优先级是大于*的,那么在*pfun1左右加上括号之后,*就将与pfun1变量名进行结合,这就说明了pfun1是一个指针变量而去掉变量名之后,就是一个函数,这就说明了pfun1是一个指向函数的指针变量,所以能够存储函数的地址。
接下来带大家来看一下,pfun2到底是一个什么!因为pfun2的左侧的操作符是*,而右侧的操作符是(),很明显,()的优先级比*要高,所以pfun2先与()进行结合,构成函数,而没有形成指针变量。void*是函数pfun2的返回类型,此处我们就可以进行下结论了,即pfun2是一个函数名,函数的返回类型是void *类型。
这个地方相信已经给大家讲明白了!其实这些在清楚的了解了那些操作符的优先级和结合性顺序之后也并不难理解!
既然我们已经理解了函数指针的相关知识,我们就先简单的运用一下吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> int add (int a, int b) { return a + b; } int main () { int (*padd)(int a, int b) = add; int sum = (*padd)(3 , 5 ); printf ("%d " , sum); return 0 ; }
那么我们该如何取理解上面的两种调用方法呢?其实也不难,我们取理解一下函数名的概念就能比较轻松的理解上面的两种调用方法,函数名和&函数名代表的含义是相同的 ,都是表示的是函数的地址,下面我会再给出一段代码来帮助大家进行理解!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> int add (int x,int y) { return x + y; } int main () { int (*p)(int x, int y); p = add; int sum = p(3 , 4 ); return 0 ; }
当然,如果你不相信的话,可以自己在编译器上试一试就ok!
6. 函数指针数组
数组是一个存放相同类型数据的存储空间,那我们已经学习了指针数组。
比如:
1 2 int *arr[10]; //数组的每个元素是int*
那要把函数的地址存到一个数组中,那这个数组就叫函数指针数组 ,那函数指针的数组如何定义呢?
1 2 3 int (*parr1[10 ])();int *parr2[10 ]();int (*)() parr3[10 ];
答案是:parr1 。parr1 先和 [] 结合,说明 parr1是数组,数组的内容是什么呢? 是 int (*)() 类型的函数指针。这个地方怎么看出来的呢?我们在数组中知道,**对于数组来说,当我们去掉数组名和[]及[]中的数字之后就知道了数组中元素的类型,**对于上面的parr1,我们也能用类似的方法,当我们将parr1[10]去掉之后,剩下的就是数组元素的类型,即int (*)(),这就是数组元素的类型,即函数指针类型!
函数指针数组的用途:转移表
例子:(计算器)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <stdio.h> int add (int a, int b) { return a + b; } int sub (int a, int b) { return a - b; } int mul (int a, int b) { return a * b; } int div (int a, int b) { return a / b; } int main () { int x, y; int input = 1 ; int ret = 0 ; int (*p[5 ])(int x, int y) = { 0 , add, sub, mul, div }; while (input) { printf ("*************************\n" ); printf (" 1:add 2:sub \n" ); printf (" 3:mul 4:div \n" ); printf ("*************************\n" ); printf ("请选择:" ); scanf ("%d" , &input); if ((input <= 4 && input >= 1 )) { printf ("输入操作数:" ); scanf ("%d %d" , &x, &y); ret = (*p[input])(x, y); } else printf ("输入有误\n" ); printf ("ret = %d\n" , ret); } return 0 ; }
通过上面的程序,我们能够实现简单的计算,并且相比不使用函数指针数组即使用if或者switch进行条件分支的情况,在后续的修改上,我们将会更加的便捷,代码的重复性相对减少!
7.回调函数 7.1回调函数的定义
回调函数:是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个 函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数 的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
7.2 回调函数的简单应用—-简易计算器
实际上,对于我们上面实现的简易计算器,还有另一种实现方法,就是通过回调函数的方法,接下来给大家进行演示一下!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <stdio.h> int add (int a, int b) { return a + b; } int sub (int a, int b) { return a - b; } int mul (int a, int b) { return a * b; } int div (int a, int b) { return a / b; } void Calc (int (*ptrf)()) { int x = 0 ; int y = 0 ; printf ("输入操作数:" ); scanf ("%d %d" , &x, &y); printf ("ret = %d\n" , ptrf(x,y)); } int main () { int input = 1 ; int ret = 0 ; do { printf ("*************************\n" ); printf (" 1:add 2:sub \n" ); printf (" 3:mul 4:div \n" ); printf ("*************************\n" ); printf ("请选择:" ); scanf ("%d" , &input); switch (input) { case 1 : Calc(add); break ; case 2 : Calc(sub); break ; case 3 : Calc(mul); break ; case 4 : Calc(div); break ; case 0 : printf ("退出程序\n" ); break ; default : printf ("选择错误,请重新输入!\n" ); break ; } } while (input); return 0 ; }
在上面的这段代码中,在Calc中被调用的函数就是回调函数!
7.3 回调函数的应用—-qsort ()函数
首先先带大家了解一下qsort()库函数!
在设计比较函数时,要根据下面的进行设计,此时如果按照下面的进行设计的话,就是升序函数!
这个地方呢,相信大家光看我上面列出来的图片大家肯定是看不明白的,下面我将带大家来具体了解一下这个函数的具体使用以及每个参数具体代表的是什么!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdio.h> #include <stdlib.h> int cmp_int (const void * e1, const void * e2) { return *(int *)e2 - *(int *)e1; } int main () { int arr[] = { 1 ,2 ,3 ,4 ,5 }; int sz = sizeof (arr) / sizeof (arr[0 ]); int (*cmp)(const void * e1, const void * e2) = cmp_int; qsort(arr, sz, sizeof (arr[0 ]),(*cmp)); for (int i = 0 ; i < 5 ; i++) { printf ("%d " , arr[i]); } return 0 ; } #include <stdio.h> #include <stdlib.h> #include <string.h> struct student { char name[20 ]; int age; }; int cmp_by_name (const void * e1, const void * e2) { return strcmp (((struct student*)e1)->name, ((struct student*)e2)->name); } int main () { struct student students [3] ="zhangsan" ,18 },{"lisi" ,19 },{"wangwu" ,20 } }; int sz = sizeof (students) / sizeof (students[0 ]); qsort(students, sz, sizeof (students[0 ]), cmp_by_name); }
上面呢,给大家举了排序整型与结构体元素时的情况,相信大家应该了解了qsort()函数的具体的使用了,下面将是一个比较难的部分,就是我们用冒泡排序的方法自己设计一个能够排序不同元素类型的排序算法。
7.4 冒泡排序算法(仿照qsort()的形式) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Swap (char * buf1, char * buf2, int width) { int i = 0 ; for (i = 0 ; i < width; i++) { char tmp = *buf1; *buf1 = *buf2; *buf2 = tmp; buf1++; buf2++; } } void bubble_sort (void * base, int sz, int width, int (*cmp)(void * e1, void * e2)) { int i = 0 ; for (i = 0 ; i < sz - 1 ; i++) { int j = 0 ; for (j = 0 ; j < sz - 1 - i; j++) { if (cmp((char *)base + j * width, (char *)base + (j + 1 ) * width)>0 ) { Swap((char *)base + j * width, (char *)base + (j + 1 ) * width,width); } } } }
在这里面起始代码的逻辑还是相对比较复杂的,主要是有些地方不太容易理解,这里我给大家点一个点,就是我们在进行交换的时候,因为我们不知道元素类型是什么,即交换时一次交换几个字节,所以在这个地方我们统一将其转换成char*类型,就是每一次交换的元素数目是一个,交换的次数就是每个元素所占的字节的数目,这个地方并不难理解,但很难想到这种设计的方法,至于其它地方,就与前面的qsort()算法大同小异了,希望大家能够细细体会!
8. 指向函数指针数组的指针
指向函数指针数组的指针是一个指针指针指向一个 数组 ,数组的元素都是函数指针。
如何定义?下面就是定义的代码:
1 2 3 4 5 6 7 8 9 #include <stdio.h> int main () { int (*pfarr[4 ])(int , int ); int (*(*ppfarr)[4 ])(int , int ) = &pfarr; return 0 ; }
在这个地方,我觉得可能有人问我:这个你是怎么读的啊,这个这么复杂,其实读的方法并不复杂,就是自右向左,由外向内 !
9. 指针和数组笔试题及解析 9.1一维数组 9.1.1 一维整型数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> int main () { int a[] = { 1 ,2 ,3 ,4 }; printf ("%d\n" , sizeof (a)); printf ("%d\n" , sizeof (a + 0 )); printf ("%d\n" , sizeof (*a)); printf ("%d\n" , sizeof (a + 1 )); printf ("%d\n" , sizeof (a[1 ])); printf ("%d\n" , sizeof (&a)); printf ("%d\n" , sizeof (*&a)); printf ("%d\n" , sizeof (&a + 1 )); printf ("%d\n" , sizeof (&a[0 ])); printf ("%d\n" , sizeof (&a[0 ] + 1 )); return 0 ; }
运行截图:
很明显,与我们上面进行解析的一样! 下面是一个帮助理解的图:
9.1.2 一维字符数组 (1)以{}定义的一维字符数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <stdio.h> int main () { char arr[] = { 'a' ,'b' ,'c' ,'d' ,'e' ,'f' }; printf ("%d\n" , sizeof (arr)); printf ("%d\n" , sizeof (arr + 0 )); printf ("%d\n" , sizeof (*arr)); printf ("%d\n" , sizeof (arr[1 ])); printf ("%d\n" , sizeof (&arr)); printf ("%d\n" , sizeof (&arr + 1 )); printf ("%d\n" , sizeof (&arr[0 ] + 1 )); printf ("%d\n" , strlen (arr)); printf ("%d\n" , strlen (arr + 0 )); printf ("%d\n" , strlen (*arr)); printf ("%d\n" , strlen (arr[1 ])); printf ("%d\n" , strlen (&arr)); printf ("%d\n" , strlen (&arr + 1 )); printf ("%d\n" , strlen (&arr[0 ] + 1 )); return 0 ; }
此处就不放运行截图了,因为程序发生了崩溃现象!
(2)以“”定义的一维字符数组
1‘用字符数组进行存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> int main () { char arr[] = "abcdef" ; printf ("%d\n" , sizeof (arr)); printf ("%d\n" , sizeof (arr + 0 )); printf ("%d\n" , sizeof (*arr)); printf ("%d\n" , sizeof (arr[1 ])); printf ("%d\n" , sizeof (&arr)); printf ("%d\n" , sizeof (&arr + 1 )); printf ("%d\n" , sizeof (&arr[0 ] + 1 )); printf ("%d\n" , strlen (arr)); printf ("%d\n" , strlen (arr + 0 )); printf ("%d\n" , strlen (*arr)); printf ("%d\n" , strlen (arr[1 ])); printf ("%d\n" , strlen (&arr)); printf ("%d\n" , strlen (&arr + 1 )); printf ("%d\n" , strlen (&arr[0 ] + 1 )); return 0 ; }
2’用字符指针进行存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> int main () { char * p = "abcdef" ; printf ("%d\n" , sizeof (p)); printf ("%d\n" , sizeof (p + 1 )); printf ("%d\n" , sizeof (*p)); printf ("%d\n" , sizeof (p[0 ])); printf ("%d\n" , sizeof (&p)); printf ("%d\n" , sizeof (&p + 1 )); printf ("%d\n" , sizeof (&p[0 ] + 1 )); printf ("%d\n" , strlen (p)); printf ("%d\n" , strlen (p + 1 )); printf ("%d\n" , strlen (*p)); printf ("%d\n" , strlen (p[0 ])); printf ("%d\n" , strlen (&p)); printf ("%d\n" , strlen (&p + 1 )); printf ("%d\n" , strlen (&p[0 ] + 1 )); return 0 ; }
此处进行解释一下strlen(&p),因为此处是从p的地址开始的,而p的地址是00 f7 7b d0(左边是高地址位,右边是低地址位),在这个地方,此时是16进制的,一个16进制位代表4个bit位,8个bie位代表一个字节,即上面的2位才是1个字节,而strlen()函数是从低地址位开始的,所以d0 7b f7总共是三个非0的字节,所以上面的结果才是3个字节。
9.2 二维数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> int main () { int a[3 ][4 ] = { 0 }; printf ("%d\n" , sizeof (a)); printf ("%d\n" , sizeof (a[0 ][0 ])); printf ("%d\n" , sizeof (a[0 ])); printf ("%d\n" , sizeof (a[0 ] + 1 )); printf ("%d\n" , sizeof (*(a[0 ] + 1 ))); printf ("%d\n" , sizeof (a + 1 )); printf ("%d\n" , sizeof (*(a + 1 ))); printf ("%d\n" , sizeof (&a[0 ] + 1 )); printf ("%d\n" , sizeof (*(&a[0 ] + 1 ))); printf ("%d\n" , sizeof (*a)); printf ("%d\n" , sizeof (a[3 ])); return 0 ; }
总结:
数组名的意义:
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。 &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。 除此之外所有的数组名都表示首元素的地址。
10. 指针相关的笔试题及解析 10.1 笔试题1 题目:
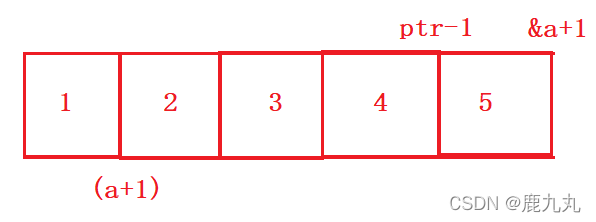
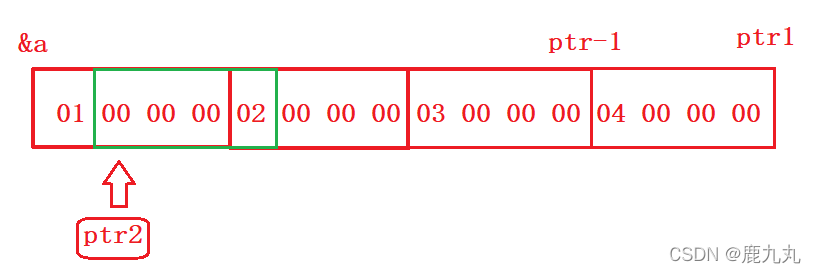
1 2 3 4 5 6 7 8 9 #include <stdio.h> int main () { int a[5 ] = { 1 , 2 , 3 , 4 , 5 }; int * ptr = (int *)(&a + 1 ); printf ("%d,%d" , *(a + 1 ), *(ptr - 1 )); return 0 ; }
运行截图:
文字解析:
a是数组首元素的地址,类型为int *,数组首元素的地址+1,跳过一个整型元素,即数组第二个元素的地址,对其进行解引用 就是a[1],所以输出结果为2。
&a是数组的地址,数组地址+1就是跳过一个数组大小的地址,此时类型为int (*)[5],对其进行强制类型转换 后,类型变为了(int*),-1就回退一个整型元素的大小,此时指针指向的元素是5。
画图解析:
10.2 笔试题2 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 程序的结果是什么? #include <stdio.h> struct Test { int Num; char * pcName; short sDate; char cha[2 ]; short sBa[4 ]; }*p; int main () { p = 0x100000 ; printf ("%p\n" , p + 0x1 ); printf ("%p\n" , (unsigned long )p + 0x1 ); printf ("%p\n" , (unsigned int *)p + 0x1 ); return 0 ; }
运行截图:
代码解析:
p的类型为(struct Test*),所以+1后跳过12个字节,在进行(unsigned long)强制类型转换后,+1后跳过1个字节,在进行(unsigned int*)强制类型转换后,加1跳过一个整型的大小,即4个字节。
10.3 笔试题3 代码:
1 2 3 4 5 6 7 8 int main () { int a[4 ] = { 1 , 2 , 3 , 4 }; int *ptr1 = (int *)(&a + 1 ); int *ptr2 = (int *)((int )a + 1 ); printf ( "%x,%x" , ptr1[-1 ], *ptr2); return 0 ; }
运行截图:
画图解析:
代码解析:
&a得到的是数组a的地址,+1即跳过一个数组的大小,对其进行强制类型转换后类型变成了int*,ptr[-1]=ptr+(-1),因为此时的类型是int*,所以回退的是一个整型的空间,因为其类型是int*,一次能够访问4个字节,所以对其进行输出后的结果是4。
对a进行强制类型转换后a的类型就变成了int,+1就是简单的加1,跳过一个字节,跳过一个字节在上图中体现的就是跳过两位数组,此时指向了00,因为其类型是int*,一次能够访问4个字节,所以取出的数组就是00 00 00 02,因为其是小端存储,并且是按照16进制形式进行打印,所以打印结果是20 00 00 00。
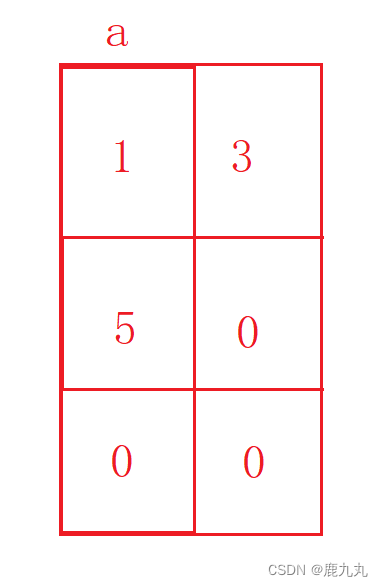
10.4 笔试题4 代码:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> #include <stdio.h> int main () { int a[3 ][2 ] = { (0 , 1 ), (2 , 3 ), (4 , 5 ) }; int * p; p = a[0 ]; printf ("%d" , p[0 ]); return 0 ; }
运行截图:
代码解析:
此处有一个需要注意的点,就是{}中的()中的代码是逗号表达式 ,即代码等价于int a[3][2] = {1,3,5},即最终数组初始化的结果就像下方画的图一样!
a[0]是第一行的数组名,而此处的数组名代表的是第一行第一个元素的地址 ,即a的地址,p[0]代表的是*(p+0),p+0之后并未发生改变,仍然是第一行第一个元素的地址,且此时的类型也是int*,对其进行解引用之后就是数组第一行第一个元素,即1。
注意:
1、()中的内容是逗号表达式!
2、p[0] = *(p+0)。
10.5 笔试题5 代码:
1 2 3 4 5 6 7 8 int main () { int a[5 ][5 ]; int (*p)[4 ]; p = a; printf ("%p,%d\n" , &p[4 ][2 ] - &a[4 ][2 ], &p[4 ][2 ] - &a[4 ][2 ]); return 0 ; }
运行截图:
代码解析:
10.6 笔试题6 代码:
1 2 3 4 5 6 7 8 9 #include <stdio.h> int main () { int aa[2 ][5 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 }; int * ptr1 = (int *)(&aa + 1 ); int * ptr2 = (int *)(*(aa + 1 )); printf ("%d,%d" , *(ptr1 - 1 ), *(ptr2 - 1 )); return 0 ; }
运行截图:
代码解析:
&aa+1就是跳过一个二维数组,指向10的后面,此时的类型是int (*)[2][5],强制类型转换后类型变成int*。此时使ptr1-1就是回退一个整型元素,指向元素10,解引用之后得到元素10。
aa是二维数组的数组名,数组名是数组首元素的地址,即第一行的地址,aa+1跳过一行,此时是数组第二行的地址,对其进行解引用之后就是第二行的数组名,再进行请值类型转换后类型变成了int *(当然,此处就算不进行强制类型转换类型也是int*,因为第二行数组名是一维数组,数组名代表首元素的地址,其类型自然就是int*)。此时使ptr2-1就是回退一个元素,指向元素5,解引用之后得到元素5。
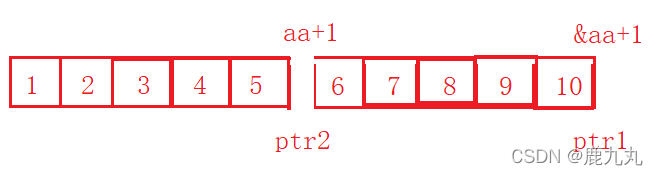
10.7 笔试题7 代码:
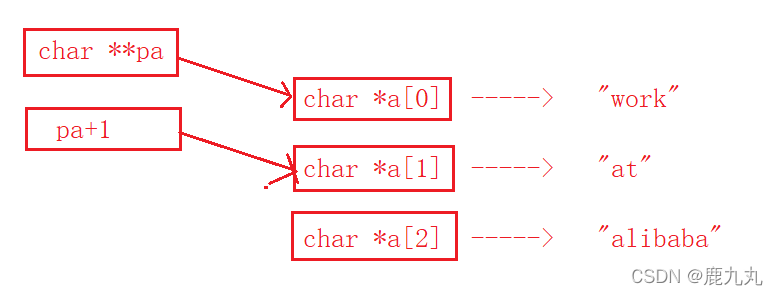
1 2 3 4 5 6 7 8 9 #include <stdio.h> int main () { char * a[] = { "work" ,"at" ,"alibaba" }; char ** pa = a; pa++; printf ("%s\n" , *pa); return 0 ; }
运行截图:
代码分析:
如何理解char *a = { “work”,”at”,”alibaba” };这行代码呢?
其实这行代码等价于下面的这三行代码:
a[0] = “work”;
a[1] = “at”;
a[2] = “alibaba”;
其中a[0]、a[1]、a[2]的类型都是字符指针类型,都是存储的后面字符串常量的首地址。
a代表的是数组首元素的地址,即a[0]的地址,pa的类型是char**,即二级指针,+1后跳过一个char *类型,即pa++后pa指向的是a[1],即存储的是a[1]的地址,对其进行解引用之后得到的就是字符串常量中”at”中a的地址。
10.8 笔试题8 代码:
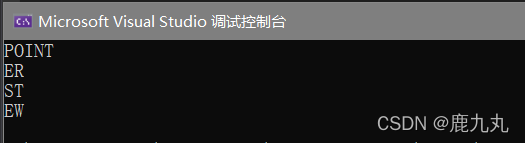
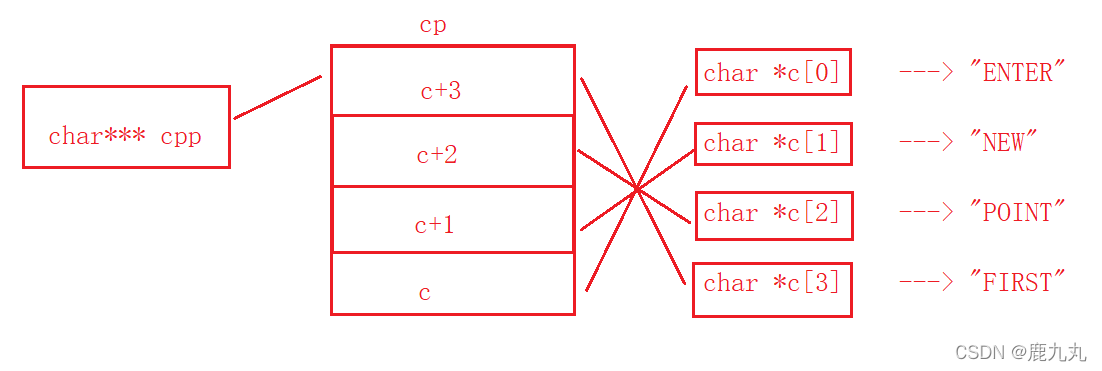
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> int main () { char * c[] = { "ENTER" ,"NEW" ,"POINT" ,"FIRST" }; char ** cp[] = { c + 3 ,c + 2 ,c + 1 ,c }; char *** cpp = cp; printf ("%s\n" , **++cpp); printf ("%s\n" , *-- * ++cpp + 3 ); printf ("%s\n" , *cpp[-2 ] + 3 ); printf ("%s\n" , cpp[-1 ][-1 ] + 1 ); return 0 ; }
运行截图:
代码分析:
对于**++cpp,这个表达式来说,*和++优先级相同,但是结合性是自右向左,所以先进行++操作,++后cpp指向cp[1],即图中的c+2,对其进行一次解引用之后可以得到cp[1]中存放的地址,二次解引用之后可以得到c[2]中存放的即”POINT”首元素即P的地址,所以打印结果应该是POINT。
对于*–*++cpp+3这个表达式来说,,首先是cpp自增1,cpp指向了图中的c+1(前一个表达式中已经自增过一次了),此时进行解引用之后得到了c+1,然后进行自减,此时就变成了c,然后再对其进行解引用之后得到了”ENTER”中字符E的地址 ,此时再进行加3,然后得到的就是E的地址,所以输出结果为ER。
对于*cpp[-2]+3这个表达式来说,这个表达式等价于**(cpp-2)+3,首先是cpp-2,因为之前cpp指向的是图中的c+1,-2之后指向的是c+3,对其进行解引用之后得到的是c[3]的地址,然后进行解引用之后就得到了FIRST的地址,然后对其进行+3,就得到了S的地址,所以打印结果为ST。
对于cpp[-1][-1]+1这个表达式来说,这个表达式等价于*(*(cpp-1)-1)+1,首先cpp-1,从指向c+1这个位置指向 了c+2这个位置,解引用得到的就是c+2,然后进行-1,变成了了c+1,然后解引用之后得到了c[1]的内容,其实是N的地址,N的地址+1得到的就是E的地址,所以输出的结果是EW。
1. 为什么存在动态内存分配 我们已经掌握的内存开辟方式有:
1 2 int val = 20 ;char arr[10 ] = { 0 };
但是上述的开辟空间的方式有两个特点:
1. 空间开辟大小是固定的。
2. 数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。
但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小在程序运行的时候才能知道, 那数组的编译时开辟空间的方式就不能满足了。 这时候就只能使用动态存开辟了。
2. 动态内存函数的介绍 2.1 malloc和free C语言提供了一个动态内存开辟的函数:
1 void * malloc (size_t size) ;
这个函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。
(1)如果开辟成功,则返回一个指向开辟好空间的指针。
(2)如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。
(3)返回值的类型是 void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己来决定。(在gcc编译器下是不需要进行手动转换的,编译器是会自动进行转换的)
(4)如果参数 size 为0,malloc的行为是标准是未定义的,取决于编译器。
C语言提供了另外一个函数free,专门是用来做动态内存的释放和回收的,函数原型如下:
free函数用来释放动态开辟的内存。
(1)如果参数 ptr 指向的空间不是动态开辟的,那free函数的行为是未定义的。
(2)如果参数 ptr 是NULL指针,则函数什么事都不做。
注意:malloc和free都声明在 stdlib.h 头文件中。
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> int main () { int * p = (int *)malloc (sizeof (int ) * 10 ); if (p == NULL ) { printf ("%s\n" , strerror(errno)); } else { int i = 0 ; for (i = 0 ; i < 10 ; i++) { *(p+i) = i; } for (i = 0 ; i < 10 ; i++) { printf ("%d " , *(p + i)); } } free (p); p = NULL ; return 0 ; }
2.2 calloc C语言还提供了一个函数叫 calloc , calloc 函数也用来动态内存分配。原型如下:
1 void * calloc (size_t num, size_t size) ;
(1)函数的功能是为 num 个大小为 size 的元素开辟一块空间,并且把空间的每个字节初始化为0。
(2)与函数 malloc 的区别只在于 calloc 会在返回地址之前把申请的空间的每个字节初始化为全0。
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> #include <stdlib.h> int main () { int * p = NULL ; p = (int *)calloc (10 ,sizeof (int )); if (p != NULL ) { for (int i = 0 ; i < 10 ; i++) { p[i] = i; } } free (p); return 0 ; }
2.3 realloc
realloc函数的出现让动态内存管理更加灵活。
有时会我们发现过去申请的空间太小了,有时候我们又会觉得申请的空间过大了,那为了合理的时 候内存,我们一定会对内存的大小做灵活的调整。那 realloc 函数就可以做到对动态开辟内存大小 的调整。
函数原型如下:
1 void * realloc (void *ptr, size_t size) ;
(1)ptr 是要调整的内存地址
(2)size 调整之后新大小
(3)返回值为调整之后的内存起始位置。
(4)这个函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到新的空间。
(5)内存追加失败就会返回空指针。
注意:realloc()参数中的指针如果是空指针的情况下与malloc是等价的!
realloc在调整内存空间的是存在两种情况:
情况1:原有空间之后有足够大的空间
情况2:原有空间之后没有足够大的空间
情况1
当是情况1的时候,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化。
情况2
当是情况2 的时候,原有空间之后没有足够多的空间时,扩展的方法是:在堆空间上另找一个合适大小 的连续空间来使用。这样函数返回的是一个新的内存地址。
由于上述的两种情况,realloc函数的使用就要注意一些。
综上来看,我们在realloc函数追加后将新的地址赋给一个新的指针变量,一方面防止上面的情况2,另一方面防止开辟内存失败后返回一个空指针,这两种情况都是为了防止之前开辟的内存空间丢失,没有指针变量指向即无法找到,造成内存泄露问题,另外需要注意在开辟后使用这块内存空间之前,我们一定要进行判断,判断指针是否为空指针。
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <stdlib.h> int main () { int * p = NULL ; p = (int *)calloc (5 ,sizeof (int )); if (p != NULL ) { for (int i = 0 ; i < 5 ; i++) { p[i] = i; } } int *ptr = realloc (p,40 ); if (ptr != NULL ) { for (int i = 0 ; i < 10 ; i++) { ptr[i] = i; } } free (ptr); return 0 ; }
3. 常见的动态内存错误 3.1 对NULL指针的解引用操作 1 2 3 4 5 6 void test () { int * p = (int *)malloc (INT_MAX / 4 ); *p = 20 ; free (p); }
3.2 对动态开辟空间的越界访问 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void test () { int i = 0 ; int * p = (int *)malloc (10 * sizeof (int )); if (NULL == p) { exit (EXIT_FAILURE); } for (i = 0 ; i <= 10 ; i++) { *(p + i) = i; } free (p); }
3.3 对非动态开辟内存使用free释放 1 2 3 4 5 6 7 void test () { int a = 10 ; int * p = &a; free (p); } }
3.4 使用free释放一块动态开辟内存的一部分 1 2 3 4 5 6 void test () { int * p = (int *)malloc (100 ); p++; free (p); }
注意:使用free进行释放的时候,必须从开辟的起始位置进行释放,其它位置不行!
3.5 对同一块动态内存多次释放 1 2 3 4 5 6 void test () { int * p = (int *)malloc (100 ); free (p); free (p); }
如何避免这种错误?
每次在使用free进行释放的时候,都要将指针置为空指针,然后即使我们再次对空指针进行free了,这个操作也是无效的。
3.6 动态开辟内存忘记释放(内存泄漏) 1 2 3 4 5 6 7 8 9 10 11 12 13 void test () { int * p = (int *)malloc (100 ); if (NULL != p) { *p = 20 ; } } int main () { test(); while (1 ); }
目录
4. 几个经典的笔试题
4.1 题目1
4.2 题目2
4.3 题目3
4.4 题目4
5. C/C++程序的内存开辟
6. 柔性数组
6.1 柔性数组的特点
6.2 柔性数组的使用
6.3 柔性数组的优势
4. 几个经典的笔试题 4.1 题目1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdio.h> #include <stdlib.h> void GetMemory (char * p) { p = (char *)malloc (100 ); } void Test (void ) { char * str = NULL ; GetMemory(str); strcpy (str, "hello world" ); printf (str); } int main () { Test(); return 0 ; }
修改方案1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <stdio.h> #include <stdlib.h> void GetMemory (char ** p) { *p = (char *)malloc (100 ); } void Test (void ) { char * str = NULL ; GetMemory(&str); strcpy (str, "hello world" ); printf (str); free (str); str = NULL ; } int main () { Test(); return 0 ; }
修改方案2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdio.h> #include <stdlib.h> char * GetMemory (char * p) { p = (char *)malloc (100 ); return p; } void Test (void ) { char * str = NULL ; str = GetMemory(str); strcpy (str, "hello world" ); printf (str); free (str); str = NULL ; } int main () { Test(); return 0 ; }
4.2 题目2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> char * GetMemory (void ) { char p[] = "hello world" ; return p; } void Test (void ) { char * str = NULL ; str = GetMemory(); printf (str); } int main () { Test(); return 0 ; }
修改方案1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> char * GetMemory (void ) { char *p = "hello world" ; return p; } void Test (void ) { char * str = NULL ; str = GetMemory(); printf (str); } int main () { Test(); return 0 ; }
修改方案2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> char * GetMemory (void ) { static char p[] = "hello world" ; return p; } void Test (void ) { char * str = NULL ; str = GetMemory(); printf (str); } int main () { Test(); return 0 ; }
4.3 题目3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <stdlib.h> void GetMemory (char ** p, int num) { *p = (char *)malloc (num); } void Test (void ) { char * str = NULL ; GetMemory(&str, 100 ); strcpy (str, "hello" ); printf (str); } int main () { Test(); return 0 ; }
修改方案:
1 2 3 4 5 6 7 8 9 10 11 12 13 void GetMemory (char ** p, int num) { *p = (char *)malloc (num); } void Test (void ) { char * str = NULL ; GetMemory(&str, 100 ); strcpy (str, "hello" ); printf (str); free (str); str = NULL ; }
4.4 题目4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> #include <stdlib.h> #include <string.h> void Test (void ) { char * str = (char *)malloc (100 ); strcpy (str, "hello" ); free (str); if (str != NULL ) { strcpy (str, "world" ); printf (str); } } int main () { Test(); return 0 ; }
运行截图:
C/C++程序内存分配的几个区域:
1. 栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结 束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是 分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返 回地址等。
2. 堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。分 配方式类似于链表。
3. 数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放。
4. 代码段:存放函数体(类成员函数和全局函数)的二进制代码。
有了这幅图,我们就可以更好的理解 static关键字修饰局部变量的例子了。 实际上普通的局部变量是在栈区分配空间的,栈区的特点是在上面创建的变量出了作用域就销毁。 但是被static修饰的变量存放在数据段(静态区),数据段的特点是在上面创建的变量,直到程序 结束才销毁,所以生命周期变长。
6. 柔性数组
C99 中,结构中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。
例如:
1 2 3 4 5 struct st_type { int i; int a[0 ]; }type_a;
有些编译器会报错无法编译可以改成:
1 2 3 4 5 struct st_type { int i; int a[]; }type_a;
上面这两种形式的意义其实是完全相同的。
6.1 柔性数组的特点
(1)结构中的柔性数组成员前面必须至少一个其他成员。
(2)sizeof 返回的这种结构大小不包括柔性数组的内存。
(3)包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
例如:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> struct st_type { int i; int a[]; }type_a; int main () { printf ("%d" , sizeof (struct st_type)); return 0 ; }
6.2 柔性数组的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdio.h> #include <stdlib.h> struct S { int n; int arr[0 ]; }; int main () { struct S * ps =struct S*)malloc (sizeof (struct S) + 5 * sizeof (int )); ps->n = 100 ; int i = 0 ; for (i = 0 ; i < 5 ; i++) { ps->arr[i] = i; } struct S * ptr =realloc (ps, 44 ); if (ptr != NULL ) { ps = ptr; } for (i = 5 ; i < 10 ; i++) { ps->arr[i] = i; } for (i = 0 ; i < 10 ; i++) { printf ("%d " , ps->arr[i]); } free (ps); return 0 ; }
另一种类似柔性数组的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <stdlib.h> struct S { int n; int * arr; }; int main () { struct S * ps =struct S*)malloc (sizeof (struct S)); ps->arr = (int *)malloc (sizeof (int ) * 5 ); int i = 0 ; for (i = 0 ; i < 5 ; i++) { ps->arr[i] = i; } int * ptr = realloc (ps->arr, 10 *sizeof (int )); if (ptr != NULL ) { ps->arr = ptr; } for (i = 5 ; i < 10 ; i++) { ps->arr[i] = i; } for (i = 0 ; i < 10 ; i++) { printf ("%d " , ps->arr[i]); } free (ps->arr); free (ps); return 0 ; }
两种方法有什么区别呢?
首先是两者空间上的大小,上面柔性数组的空间大小为4,而下面的仿柔性数组的空间大小为8。
柔性数组只能出现在结构体中,但是下面这种方法却是通用的,因为下面的方法本质上就是一个指针来指向一块动态开辟的内存空间。
6.3 柔性数组的优势
一个好处是:方便内存释放 如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给 用户。用户调用free可以释放结构体,但是用户并不知道这个结构体内的成员也需要free,所以你 不能指望用户来发现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好 了,并返回给用户一个结构体指针,用户做一次free就可以把所有的内存也给释放掉。
第二个好处是:这样有利于访问速度. 连续的内存有益于提高访问速度,也有益于减少内存碎片。
1. 为什么使用文件
使用文件我们可以将数据直接存放在电脑的硬盘上,做到了数据的持久化。
2. 什么是文件
磁盘上的文件是文件。
但是在程序设计中,我们一般谈的文件有两种:程序文件、数据文件 (从文件功能的角度来分类的)。
2.1 程序文件
包括源程序文件 (后缀为.c),目标文件 (windows环境后缀为.obj),可执行程序 (windows环境 后缀为.exe)。
2.2 数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件, 或者输出内容的文件。
在以前处理数据的输入输出都是以终端为对象的,即从终端的键盘输入数据,运行结果显示到显 示器上。
其实有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理 的就是磁盘上文件。
2.3 文件名
一个文件要有一个唯一的文件标识,以便用户识别和引用。
文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt 为了方便起见,文件标识常被称为文件名。
3. 文件的打开和关闭
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名 字,文件状态及文件当前的位置等)。
这些信息是保存在一个结构体变量中的。
该结构体类型是有系统 声明的,取名FILE.
例如,VS2013编译环境提供的 stdio.h 头文件中有以下的文件类型申明:
1 2 3 4 5 6 7 8 9 10 11 struct _iobuf { char * _ptr; int _cnt; char * _base; int _flag; int _file; int _charbuf; int _bufsiz; char * _tmpfname; }; typedef struct _iobuf FILE ;
不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息, 使用者不必关心细节。
一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
下面我们可以创建一个FILE*的指针变量:
定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变 量)。
通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联 的文件。
比如:
3.2 文件的打开和关闭
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。
在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件的关系。
ANSIC 规定使用fopen函数来打开文件,fclose来关闭文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 FILE* fopen (const char * filename, const char * mode) ; int fclose (FILE* stream) ;
打开方式下所示:
文件使用方式
含义
如果指定文件不存在
“r”(只读)
为了输入数据,打开一个已经存在的文本文件
出错
“w”(只写)
为了输出数据,打开一个文本文件
建立一个新的文件
“a”(追加)
向文本文件尾添加数据
建立一个新的文件
“rb”(只读)
为了输入数据,打开一个二进制文件
出错
“wb”(只写)
为了输出数据,打开一个二进制文件
建立一个新的文件
“ab”(追加)
向一个二进制文件尾添加数据
出错
“r+”(读写)
为了读和写,打开一个文本文件
出错
“w+”(读写)
为了读和写,建议一个新的文件
建立一个新的文件
“a+”(读写)
打开一个文件,在文件尾进行读写
建立一个新的文件
“rb+”(读写)
为了读和写打开一个二进制文件
出错
“wb+”(读写)
为了读和写,新建一个新的二进制文件
建立一个新的文件
“ab+”(读写)
打开一个二进制文件,在文件尾进行读和写
建立一个新的文件
实例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> int main () { FILE* pFile; pFile = fopen("myfile.txt" , "w" ); if (pFile != NULL ) { fputs ("fopen example" , pFile); fclose(pFile); } return 0 ; }
4. 文件的顺序读写
键盘:输入设备
屏幕:输出设备
键盘和屏幕是一个程序默认打开的两个流设备
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <string.h> #include <errno.h> int main () { FILE* pfwrite = fopen("text.txt" , "w" ); if (pfwrite == NULL ) { printf ("%s\n" , strerror(errno)); } fputc('b' , pfwrite); fputc('i' , pfwrite); fputc('t' , pfwrite); fclose(pfwrite); pfwrite = NULL ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <string.h> #include <errno.h> int main () { FILE* pfread = fopen("text.txt" , "r" ); if (pfread == NULL ) { printf ("%s\n" , strerror(errno)); } printf ("%c" ,fgetc(pfread)); printf ("%c" , fgetc(pfread)); printf ("%c" , fgetc(pfread)); fclose(pfread); pfread = NULL ; return 0 ; }
运行截图:
fgetc()和fputc()直接使用举例:
1 2 3 4 5 6 7 #include <stdio.h> int main () { int ch = fgetc(stdin ); fputc(ch, stdout ); return 0 ; }
运行截图:
(3)fgets()
string:数据的存储位置
n:最多读取的字符的个数
stream:读取的文件流
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <errno.h> int main () { char arr[1024 ] = { 0 }; FILE* pf = fopen("text.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); } fgets(arr, 1024 , pf); printf ("%s" , arr); fgets(arr, 1024 , pf); printf ("%s" , arr); fclose(pf); pf = NULL ; }
运行截图:
作用:写一个字符串到文件流里去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <errno.h> int main () { char arr[1024 ] = { 0 }; FILE* pf = fopen("text.txt" , "w" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); } fputs ("hello" , pf); fputs ("world" , pf); fclose(pf); pf = NULL ; }
运行后文件截图:
注意:fputs()函数不会自动带换行符
函数fgets()和函数fputs()函数直接应用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> int main () { char buf[1024 ] = { 0 }; fgets(buf, 1024 , stdin ); fputs (buf,stdout ); return 0 ;}
运行截图:
上面之所以出现一个换行符是因为我们在输入的末尾输入了一个换行符。
(5)fprintf()
对比一下printf()
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <string.h> #include <errno.h> struct S { int n; float score; char arr[10 ]; }; int main () { struct S s =100 ,3.14f ,"bit" }; FILE* pf = fopen("text.txt" , "w" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fprintf (pf, "%d %f %s" , s.n, s.score, s.arr); fclose(pf); pf = NULL ; return 0 ; }
运行后截图:
对比scanf()
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <string.h> #include <errno.h> struct S { int n; float score; char arr[10 ]; }; int main () { struct S s =0 }; FILE* pf = fopen("text.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fscanf (pf, "%d %f %s" , &s.n, &s.score, &s.arr); printf ("%d %f %s" , s.n, s.score, s.arr); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
函数fprintf()和fscanf()的直接应用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> struct S { int n; float score; char arr[10 ]; }; int main () { struct S s =0 }; fscanf (stdin , "%d %f %s" , &s.n, &s.score, &s.arr); fprintf (stdout , "%d %f %s" , s.n, s.score, s.arr); return 0 ; }
运行截图:
buffer:指针指向被写入的数据
size:被写入元素的大小,单位是字节
count:被写入的数据的数目
stream:写入的目的流
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> struct S { char name[20 ]; int age; double score; }; int main () { struct S s ="张三" ,20 ,55.6 }; FILE* pf = fopen("text.txt" , "wb" ); if (pf == NULL ) { return 0 ; } fwrite(&s, sizeof (struct S), 1 , pf); fclose(pf); pf = NULL ; return 0 ; }
(8)fread()
buffer:存储数据的位置
size:元素的大小
count:读取元素的数目
stream:指针指向的文件结构
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> struct S { char name[20 ]; int age; double score; }; int main () { struct S tmp =0 }; FILE* pf = fopen("text.txt" , "rb" ); if (pf == NULL ) { return 0 ; } fread(&tmp, sizeof (struct S), 1 , pf); printf ("%s %d %lf" , tmp.name, tmp.age, tmp.score); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
4.1 对比一组函数
scanf/fscanf/sscanf printf/fprintf/sprintf
4.1.1 了解sscanf()与sprintf()函数 (1)sscanf()
作用描述:从一个字符串中读取一段格式化的数据。
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> struct S { int n; float score; char arr[10 ]; }; int main () { struct S s =100 ,3.14 ,"hello" }; struct S tmp =0 }; char buf[1024 ] = { 0 }; sprintf (buf, "%d %f %s" , s.n, s.score, s.arr); sscanf (buf, "%d %f %s" , &(tmp.n), &(tmp.score), &(tmp.arr)); printf ("%d %f %s\n" , tmp.n, tmp.score, tmp.arr); return 0 ; }
运行截图:
(2)sprintf()
作用描述:将格式化的数据写入到一个字符串中去。
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> struct S { int n; float score; char arr[10 ]; }; int main () { struct S s =100 ,3.14 ,"hello" }; char buf[1024 ] = { 0 }; sprintf (buf, "%d %f %s" , s.n, s.score, s.arr); printf ("%s" , buf); return 0 ; }
scanf/printf 是针对标准输入流/标准输出流的 格式化输入/输出语句。
fscanf/fprintf 是针对所有输入流/所有输出流的 格式化输入输出语句,包含上面函数的功能。
sscanf/sprintf sscanf是从字符串中读取格式化的数据,sprintf是把格式化的数据输出成(存储到)字符串。
5. 文件的随机读写 5.1 fseek()
作用:移动文件指针到一个特定的位置
stream:要移动的文件指针
offset:偏移量(可以为负数,整数就是向右偏移,负数就是向左偏移)
origin:文件指针的当前位置
orifon起始位置的三个选择:
SEEK_CUR:文件指针的当前位置
SEEK_END:文件的末尾位置(在最后一个字符的后面,比如在下面的例子中就是在f的后面)
SEEK_SET:文件的起始位置
使用举例:
文件初始截图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> #include <errno.h> #include <string.h> int main () { FILE* pf = fopen("test.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fseek(pf, 2 , SEEK_CUR); int ch = fgetc(pf); printf ("%c" , ch); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
5.2 ftell()
作用:计算文件指针举例相对起始位置的偏移量
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> #include <errno.h> #include <string.h> int main () { FILE* pf = fopen("test.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fseek(pf, 2 , SEEK_CUR); int pos = ftell(pf); printf ("%d\n" , pos); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
注意:fgetc()函数读取过后文件指针会自动向后偏移一位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <errno.h> #include <string.h> int main () { FILE* pf = fopen("test.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fgetc(pf); int pos = ftell(pf); printf ("%d\n" , pos); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
5.3 rewind()
作用:使文件指针回到文件的起始位置(此时举例文件起始位置的偏移量为0)。
使用举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <errno.h> #include <string.h> int main () { FILE* pf = fopen("test.txt" , "r" ); if (pf == NULL ) { printf ("%s\n" , strerror(errno)); return 0 ; } fgetc(pf); rewind(pf); int pos = ftell(pf); printf ("%d\n" , pos); fclose(pf); pf = NULL ; return 0 ; }
运行截图:
6. 文本文件和二进制文件
根据数据的组织形式,数据文件被称为文本文件或者二进制文件。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件。
如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。
一个数据在内存中是怎么存储的呢?
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而 二进制形式输出,则在磁盘上只占4个字节(VS2013测试)。
10000在内存中的存储形式:10 27 00 00(16进制形式显示的)
测试代码:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main () { int a = 10000 ; FILE* pf = fopen("test.txt" , "wb" ); fwrite(&a, 4 , 1 , pf); fclose(pf); pf = NULL ; return 0 ; }
7. 文件读取结束的判定 7.1 被错误使用的feof
牢记:在文件读取过程中,不能用feof函数的返回值直接用来判断文件的是否结束。 而是应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束。
1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets ),如果是,就返回一个非0的值。 例如: fgetc 判断是否为 EOF fgets 判断返回值是否为 NULL
2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。 例如: fread判断返回值是否小于实际要读的个数。
正确的使用: 文本文件的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <stdlib.h> int main (void ) { int c; FILE* fp = fopen("test.txt" , "r" ); if (!fp) { perror("File opening failed" ); return EXIT_FAILURE; } while ((c = fgetc(fp)) != EOF) { putchar (c); } if (ferror(fp)) puts ("I/O error when reading" ); else if (feof(fp)) puts ("End of file reached successfully" ); fclose(fp); }
二进制文件的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <stdio.h> enum {5 };int main (void ) { double a[SIZE] = { 1. ,2. ,3. ,4. ,5. }; FILE* fp = fopen("test.bin" , "wb" ); fwrite(a, sizeof * a, SIZE, fp); fclose(fp); double b[SIZE]; fp = fopen("test.bin" , "rb" ); size_t ret_code = fread(b, sizeof * b, SIZE, fp); if (ret_code == SIZE) { puts ("Array read successfully, contents: " ); for (int n = 0 ; n < SIZE; ++n) printf ("%f " , b[n]); putchar ('\n' ); } else { if (feof(fp)) printf ("Error reading test.bin: unexpected end of file\n" ); else if (ferror(fp)) { perror("Error reading test.bin" ); } } fclose(fp); }
8.文件缓冲区 8.1 什么是文件缓冲区
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序 中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装 满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓 冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根 据C编译系统决定的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <windows.h> int main () { FILE* pf = fopen("test.txt" , "w" ); fputs ("abcdef" , pf); printf ("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n" ); Sleep(10000 ); printf ("刷新缓冲区\n" ); fflush(pf); printf ("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了\n" ); Sleep(10000 ); fclose(pf); pf = NULL ; return 0 ; }
这里可以得出一个结论: 因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文 件。 如果不做,可能导致读写文件的问题。
8.2 缓冲区存在的意义
首先,把若干字符作为一个块传输比逐个发送字符节省时间;其次,如果用户打错字符,可以直接通过键盘修改错误。当最后按下Enter键时,发送的才是正确的输入。
8.3 缓冲区的分类
C语言在不同的地方根据需要使用不同的缓冲区。
缓冲区分为两类:完全缓冲I/O和行缓冲I/O和不带缓冲。
(1)完全缓冲是指的是当前缓冲区被填满时才刷新缓冲区(内容被发送至目的地),通常出现在文件输入中。缓冲区的大小取决于系统,常见的大小是512字节和4096字节。
(2)行缓冲指的是在出现换行时刷新缓冲区。键盘输入通常是行缓冲输入,所以在按下Enter键时才刷新缓冲区。常见的例子就是getchar()函数,当程序调用getchar()函数时,程序就等着用户按键,用户输入的字符被存放在键盘缓冲区中,直到用户按回车为止(回车字符也放在缓冲区中)。当用户键入回车之后,getchar()函数才开始从键盘缓冲区中每次读入一个字符。也就是说,后续的getchar()函数调用不会等待用户按键,而直接读取缓冲区中的字符,直到缓冲区中的字符读完后,才重新等待用户按键。当缓冲区满时不会自动刷新且无法继续输入,需要按回车才可以刷新缓冲区。
(3)不带缓冲:标准输出不带缓冲(例如:cerr
(4)缓冲区的刷新(执行真正的I/O操作)
当缓冲区满时:执行flush语句;执行end语句;关闭文件。
1. 程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。 第2种是执行环境,它用于实际执行代码。
2. 详解编译+链接 2.1 翻译环境
组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人 的程序库,将其需要的函数也链接到程序中。
2.2 编译本身也分几个阶段 test.c代码:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> extern int Add (int x,int y) ;int main () { int a = 1 ; int b = 2 ; int ret = Add(a,b); printf ("%d\n" ,ret); return 0 ; }
Add.c代码:
1 2 3 4 int Add (int x,int y) { return x+y; }
2.3 运行环境
程序执行的过程:
程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
程序的执行便开始。接着便调用main函数。
开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack)(函数栈帧),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
终止程序。正常终止main函数;也有可能是意外终止。
3、预处理详解 3.1 预定义符号 1 2 3 4 5 __FILE__ __LINE__ __DATE__ __TIME__ __STDC__
这些预定义符号都是语言内置的。
下面是例子:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main () { printf ("%s\n" , __FILE__); printf ("%d\n" , __LINE__); printf ("%s\n" __DATE__); printf ("%s\n" , __TIME__); return 0 ; }
运行截图:
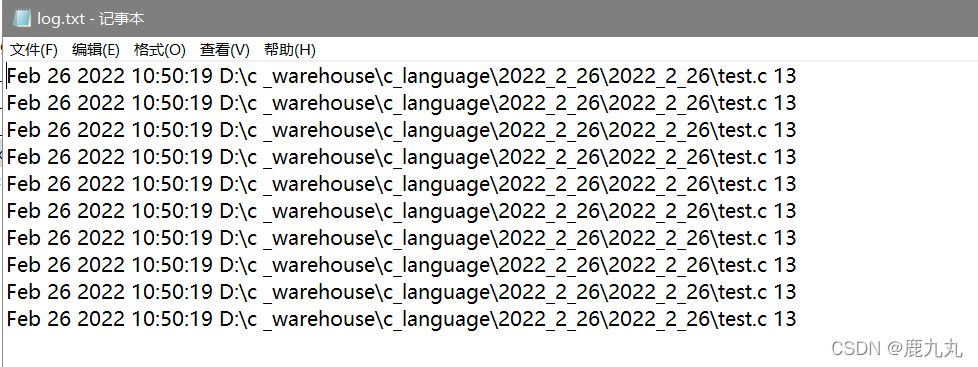
应用:记录日志
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> int main () { int i = 0 ; FILE* pf = fopen("log.txt" , "w" ); if (pf == NULL ) { return 1 ; } for (i = 0 ; i < 10 ; i++) { fprintf (pf,"%s %s %s %d\n" , __DATE__, __TIME__, __FILE__, __LINE__); } fclose(pf); pf = NULL ; return 0 ; }
运行截图:
3.2 #define 3.2.1 #define 定义标识符
举个例子:
1 2 3 4 5 6 7 8 9 #define MAX 1000 #define reg register #define do_forever for(;;) #define CASE break;case #define DEBUG_PRINT printf("file:%s\tline:%d\t \ date:%s\ttime:%s\n" ,\__FILE__,__LINE__ , \ __DATE__,__TIME__ )
提问:在define定义标识符的时候,要不要在最后加上 ; ?
比如:
1 2 #define MAX 1000; #define MAX 1000
建议不要加上 ; ,这样容易导致问题。
比如下面的场景:
1 2 3 4 if (condition) max = MAX; else max = 0 ;
这里就会出现语法错误(else没有与之匹配的if)。这里应该理清宏定义 的本质,宏定义的本质就是替换。
3.2.2 #define 定义宏
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
下面是宏的申明方式:
1 #define name( parament-list ) stuff
其中的 parament-list 是一个由逗号隔开的符号表,它们可能出现在stuff中。
注意:参数列表的左括号必须与name紧邻。如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
如:
1 #define SQUARE( x ) x * x
这个宏接收一个参数 x .
如果在上述声明之后,你把
置于程序中,预处理器就会用下面这个表达式替换上面的表达式:
警告:这个宏存在一个问题:
观察下面的代码段:
1 2 int a = 5 ;printf ("%d\n" ,SQUARE( a + 1 ) );
乍一看,你可能觉得这段代码将打印36这个值。
事实上,它将打印11。
为什么?
1 2 替换文本时,参数x被替换成a + 1 ,所以这条语句实际上变成了: printf ("%d\n" ,a + 1 * a + 1 );
这样就比较清晰了,由替换产生的表达式并没有按照预想的次序进行求值。
在宏定义上加上两个括号,这个问题便轻松的解决了:
1 #define SQUARE(x) (x) * (x)
这样预处理之后就产生了预期的效果:
1 printf ("%d\n" ,(a + 1 ) * (a + 1 ) );
这里还有一个宏定义:
1 #define DOUBLE(x) (x) + (x)
定义中我们使用了括号,想避免之前的问题,但是这个宏可能会出现新的错误。
1 2 int a = 5 ;printf ("%d\n" ,10 * DOUBLE(a));
这将打印什么值呢?
看上去,好像打印100,但事实上打印的是55.我们发现替换之后:
1 printf ("%d\n" ,10 * (5 ) + (5 ));
乘法运算先于宏定义的加法,所以出现了
55
这个问题,的解决办法是在宏定义表达式两边加上一对括号就可以了。
1 #define DOUBLE( x) ( ( x ) + ( x ) )
提示:
所以用于对数值表达式进行求值的宏定义都应该用这种方式加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间不可预料的相互作用。
3.2.3 #define 替换规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。
当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。(字符串里的宏定义不会被替换)
3.2.4 #和##
如何把参数插入到字符串中?
首先我们看看这样的代码:
1 2 3 char * p = "hello " "bit\n" ;printf ("hello" ," bit\n" );printf ("%s" , p);
这里输出的是不是hello bit ?
答案是确定的:是。
我们发现字符串是有自动连接的特点的。
1. 那我们是不是可以写这样的代码?:
1 2 3 4 5 6 #define PRINT(FORMAT, VALUE)\ printf("the value is " FORMAT"\n" , VALUE); ... PRINT("%d" , 10 ); printf ("the value is " "%d" "\n" ,10 );
运行结果:
这里只有当字符串作为宏参数的时候才可以把字符串放在字符串中。
1. 另外一个技巧是:使用 # ,把一个宏参数变成对应的字符串。
比如:
1 2 3 4 5 6 7 int i = 10 ;#define PRINT(VALUE)\ printf("the value of " #VALUE "is %d \n" , VALUE); ... PRINT( i + 3 ); printf ("the value of " "value" "is %d \n" ,VALUE);
代码中的 #VALUE 会预处理器处理为:
“VALUE”
最终的输出的结果应该是:
## 的作用
##可以把位于它两边的符号合成一个符号。
它允许宏定义从分离的文本片段创建标识符。
1 2 3 4 #define ADD_TO_SUM(sumnum, value) \ sum##num += value; ... ADD_TO_SUM(5 , 10 );
注:这样的连接必须产生一个合法的标识符。否则其结果就是未定义的。
3.2.5 带副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。副作用就是表达式求值的时候出现的永久性效果。
例如:
MAX宏可以证明具有副作用的参数所引起的问题。
1 2 3 4 5 6 #define MAX(a, b) ( (a) > (b) ? (a) : (b) ) ... x = 5 ; y = 8 ; z = MAX(x++, y++); printf ("x=%d y=%d z=%d\n" , x, y, z);
这里我们得知道预处理器处理之后的结果是什么:
1 z = ( (x++) > (y++) ? (x++) : (y++));
所以输出的结果是:
3.2.6 宏和函数对比
宏通常被应用于执行简单的运算。
比如在两个数中找出较大的一个。
1 #define MAX(a, b) ((a)>(b)?(a):(b))
那为什么不用函数来完成这个任务?
原因有二:
用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多(函数包括函数调用、逻辑运算、函数返回三个部分都需要时间。而宏的话只需要逻辑运算)。所以宏比函数在程序的规模和速度方面更胜一筹。
更为重要的是函数的参数必须声明为特定的类型。 所以函数只能在类型合适的表达式上使用。反之这个宏怎可以适用于整形、长整型、浮点型等可以用于>来比较的类型。宏是类型无关的。
宏的缺点:当然和函数相比宏也有劣势的地方:
每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
宏是没法调试的。(宏在预编译阶段就已经完成了替换,调试的时候是宏已经替换之后的代码,即调试的代码和真正调试的代码不是同一份代码)
宏由于类型无关,也就不够严谨。
宏可能会带来运算符优先级的问题,导致程容易出现错。
宏有时候可以做函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到。
1 2 3 4 5 6 #define MALLOC(num, type) (type *)malloc(num * sizeof(type)) ... MALLOC(10 , int ); (int *)malloc (10 * sizeof (int ));
宏和函数的一个对比
属性
#definde定义宏
函数
代码长度
每次使用时,宏代码都会被插入到程序中。除了非常小的宏之外,程序的长度会大幅度增长
函数代码只出现于一个地方;每次使用这个函数时,都调用那个地方的同一份代码
执行速度
更快
存在函数的调用和返回的额外开销,所以相对慢一些
操作符优先级
宏参数的求值是在所有周围表达式的上下文环境里,除非加上括号,否则邻近操作符的优先级可能会产生不可预料的后果,所以建议宏在书写的时候多些括号。
函数参数只在函数调用的时候求值一次,它的结果值传递给函数。表达式的求值结果更容易预测。
带有副作用的参数
参数可能被替换到宏体中的多个位置,所以带有副作用的参数求值可能会产生不可预料的结果。
函数参数只在传参的时候求值一次,结果更容易控制。
参数类型
宏的参数与类型无关,只要对参数的操作是合法的,它就可以使用于任何参数类型。
函数的参数是与类型有关的,如果参数的类型不同,就需要不同的函数,即使他们执行的任务是不同的。
调试
宏是不方便调试的
函数是可以逐语句调试的
递归
宏是不能递归的
函数是可以递归的
3.2.7 命名约定
一般来讲函数的宏的使用语法很相似。所以语言本身没法帮我们区分二者。
那我们平时的一个习惯是:
把宏名全部大写
函数名不要全部大写
3.3 #undef
这条指令用于移除一个宏定义。
3.4 命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出不同的一个程序的不同版本的时候,这个特性有点用处。(假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大写,我们需要一个数组能够大写。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> int main () { int array [ARRAY_SIZE]; int i = 0 ; for (i = 0 ; i < ARRAY_SIZE; i++) { array [i] = i; } for (i = 0 ; i < ARRAY_SIZE; i++) { printf ("%d " , array [i]); } printf ("\n" ); return 0 ; }
编译指令:
1 gcc -D ARRAY_SIZE=10 test.c(假设文件名为test.c)
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。因为我们有条件编译指令。
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译。
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> int main () { #if 0 for (int i = 0 ; i < 10 ; i++) { printf ("hello world\n" ); } #endif return 0 ; }
运行截图:
假如代码进行下列修改:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> int main () { #if 1 for (int i = 0 ; i < 10 ; i++) { printf ("hello world\n" ); } #endif return 0 ; }
运行截图:
注意:如果#if后面的是变量,那么结果和#if后面为0向类似,为什么会发生这种情况呢?因为变量是在运行起来之后才产生,即在运行起来之后变量才具有相应的意义。而运行起来之后,预处理指令已经消失。
常见的条件编译指令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 1. #if 常量表达式 #endif 如: #define __DEBUG__ 1 #if __DEBUG__ #endif 2. 多个分支的条件编译#if 常量表达式 #elif 常量表达式 #else #endif 3. 判断是否被定义#if defined(symbol) #ifdef symbol #if !defined(symbol) #ifndef symbol 4. 嵌套指令#if defined(OS_UNIX) #ifdef OPTION1 unix_version_option1(); #endif #ifdef OPTION2 unix_version_option2(); #endif #elif defined(OS_MSDOS) #ifdef OPTION2 msdos_version_option2(); #endif #endif
注意:在条件编译中,如果我们if后面的字符并未进行预定义过,或者在条件编译后面进行的预定义,那么这个字符就相当于0。但是我们一般既然用在条件编译指令的,前面一般即必须出现。此处我们还要注意一个点,虽然未进行预定义的字符在进行条件编译的条件判定时会被默认为0,但是在使用printf函数进行输出的时候,如果前面没有进行预定义,就无法进行输出,因为在预处理时没有相应的预处理指令来使其替换。
3.6 文件包含
我们已经知道, #include 指令可以使另外一个文件被编译。就像它实际出现于 #include 指令的地方一样。
这种替换的方式很简单:预处理器先删除这条指令,并用包含文件的内容替换。这样一个源文件被包含10次,那就实际被编译10次。
3.6.1 头文件被包含的方式
查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。
如果找不到就提示编译错误。
Linux环境的标准头文件的路径:
VS环境的标准头文件的路径:(VS2013)
1 C:\Program Files (x86) \Microsoft Visual Studio 12.0\VC\include
注意按照自己的安装路径去找。
查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
这样是不是可以说,对于库文件也可以使用 “” 的形式包含?
答案是肯定的,可以。但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
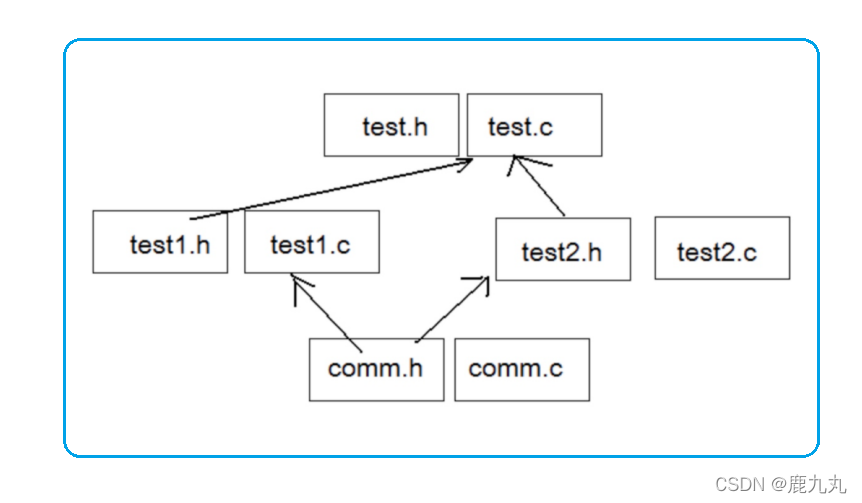
3.6.2 嵌套文件包含 如果出现这样的场景:
comm.h和comm.c是公共模块。
test1.h和test1.c使用了公共模块。
test2.h和test2.c使用了公共模块。
test.h和test.c使用了test1模块和test2模块。
这样最终程序中就会出现两份comm.h的内容。这样就造成了文件内容的重复。
如何解决这个问题?
答案:条件编译。
每个头文件的开头写:
1 2 3 4 #ifndef __TEST_H__ #define __TEST_H__ #endif
原因:因为第二次进行文件包含的时候,前面已经进行过一次条件编译,即已经定义过一次__TEST_H__,所以这一次就不会再将test.h中的文件的内容进行二次包含,即忽略掉test.h中条件编译之间的内容。
注意:不一定非要用__TEST_H__,但是一般用被包含的文件名,主要是为了更好的进行辨识与区分。
或者:
就可以避免头文件的重复引入。这种写法一般在新的编译器下支持。
C语言进阶
8、通讯录管理系统 C语言实现通讯录管理系统
C语言实现通讯录管理系统(动态内存分配版)
C语言实现通讯录管理系统(文件操作版本)